Choose timezone
Your profile timezone:
The International Conference "Distributed Computing and Grid-technologies in Science and Education" will be held at the Meshcheryakov Laboratory of Information Technologies (MLIT) of the Joint Institute for Nuclear Research (JINR). The conference GRID 2025 is dedicated to the 115th anniversary of the birth of M.G. Meshcheryakov (1910-1994) and to the 95th anniversary of the birth of N.N.Govorun (1930-1989), the prominent scientists and the Corresponding Members of the USSR Academy of Sciences. GRID 2025 is also dedicated to the 70th anniversary of the Joint Institute for Nuclear Research and to the 60th anniversary of the Meshcheryakov Laboratory of Information Technologies.
Conference Topics:
1. Distributed Computing Systems, Grid and Cloud Technologies, Storage Systems: architectures, operation, middleware and services.
2. High Performance Computing
3. Application software in HTC and HPC
4. Computing for MegaScience Projects
5. Methods and Technologies for Experimental Data Processing
Conference languages – Russian and English.
Contacts:
| Address: | 141980, Russia, Moscow region, Dubna, Joliot Curie Street, 6 |
| Phone: | (7 496 21) 64019, 64826 |
| E-mail: | grid2025@jinr.ru |
| URL: | http://grid2025.jinr.ru/ |
-
-
-
-
-
-
The GRID concept, as a computing infrastructure, according to its authors, has not been implemented by 2022 [1]. This concept was proposed by Foster and Kesselman [2] in 1999. It should be noted that this concept best suits the needs of modern applications such as on-demand computing, on-demand data storage, etc. [4]. Here is how the authors themselves formulated the main properties of the GRID infrastructure (cited follow [1]):
1. “[C]ordinate resources that are not subject to central control… (The Grid integrates and coordinates resources and users that are in different control domains—for example, a user’s desktop versus a central computing domain; different administrative units of the same company; or different companies; and solves the problems of security, policy, payment, membership, etc. that arise in these conditions. Otherwise, we are dealing with a local control system.)
2. … use of standard, open, general-purpose protocols and interfaces… (The Grid is built from multi-purpose protocols and interfaces that solve such fundamental problems as authentication, authorization, resource discovery, and resource access. … [I]t is important that these protocols and interfaces be standard and open. Otherwise, we are dealing with an application-specific system.)
3. … provide non-trivial qualities of service. (A Grid allows the use of its constituent resources in a coordinated manner to provide different qualities of service, such as response time, throughput, availability, and security, and/or the coordination of multiple types of resources to meet complex user requirements, so that the combined system provides value that is greater than the sum of its parts.)"
Foster and Kesselman in [1] have stated that none of the numerous attempts to implement the GRID concept have yet been successful. None of the projects listed in this paper have been able to implement the above requirements, to automatically minimize the execution time of an application in a computing infrastructure given its time constraints through efficient automatic management of computing load balancing between available computing devices, "non-trivial quality of service", efficient management of data transfer between application components, and the ability to increase computing resources on demand without limitation [1]. The presentation discusses the reasons for this disappointing conclusion that are computer performance, available data rates, and available mathematical methods for managing computing infrastructure resources in the early 2000s were insufficient to achieve these properties.
However, it has been significant breakthrough in the period 2014 and 2024, the server performance increased by about 7 times, supercomputer performance increased by 4 orders of magnitude, and
the maximum data rate increased from several Tbit/s to 1.1 Pbit/s over the same period [3]. These advances have stimulated a breakthrough in mathematical optimization methods based on machine learning. The point is that, given the above-mentioned speed of computation and data transfer, as well as the fact that network services and application components are easily scalable and operate in real time, to optimize resource management, data flows and computations in the next-generation computing infrastructure, let's call it Computing Centric Network (CCN), control algorithms with low time complexity are required, since time delays in decision-making become critical for the efficient operation of CCN. Classical optimization methods [3] are not suitable for this purpose, since they are based on centralized decision-making, i.e., centralized combinatorial enumeration of solution options is carried out using a (deterministic) algorithm capable of finding the best solution to the problem. In addition to computational complexity, this approach is associated with high overhead costs for collecting, processing and transmitting data between components of the computing infrastructure. The report shows that under these conditions, distributed multi-agent optimization (MAO) methods are the preferred choice. In these methods, the solution to the problem is obtained through the self-organization of a distributed set of algorithm agents capable of competition and/or cooperation and having their own criteria, preferences, and constraints. It is considered the solution is found when, the agents reach consensus (temporary equilibrium or balance of interests).
References:
The concept of “virtual testbed” of real-time computational simulation is based on high-performance algorithms for modeling the physical phenomenon under study without losing the quality of reproducible processes. One of the most complicated and comprehensive areas of this nature is naval hydrodynamics, as it requires the integration of a sufficiently big number of heterogeneous models.
Application of stable implicit numerical schemes is not considered here, since practice shows uncontrolled smoothing of hydrodynamic processes in subareas with large gradients.
Cross-cutting and ubiquitous analysis of simulation results is allowed when using explicit numerical schemes. They allow hybrid rebuilding of physical models and mathematical algorithms directly in the process of interactive control of computational processes. Nevertheless, unfortunately, often in the formulation of computational simulation follows the conclusion about impossibility of simulation with the given engineering accuracy due to excessive demand of computational resources.The problems of naval hydromechanics in the general formulation are reduced to these insoluble problems, aggravated by the lack of effective models for non-stationary processes of hydromechanics as such. In particular, unsolvable difficulties in naval hydromechanics are caused both by criteria of stability in time and by criteria of approximation smoothness for difference representation and differentiation of high-frequency non-stationary physical fields.
Engineering approaches in naval hydrodynamics (as well as in any other complex technical field) traditionally bring any technical problem to an acceptable result, with adequate correspondence to theoretical, empirical or experimental results. In practice, such explorations are limited to private solutions and are often reduced to the author's “know-how”, which is difficult to generalize and rather risky to apply in case of significant changes in the investigated objects.
Organization of expert systems based on high-performance computing systems allows to synthesize various theoretical approaches with engineering methods in naval hydromechanics. The purpose of such systems is to combine context-optimal modules for modeling, visualization and real-time data analysis.
The paper presents the idea of realizing such system in the current edition of the virtual testbed. Successive set of computational models are built from the simplest kinematic representations to complex modules requiring high-performance computing resources. The experience of specialists from researcher to navigator is formalized in the knowledge base of the expert system in the form of rules. According to these rules, based on the external conditions, the state of the object under study, the mode of motion and modeling objectives, the simplest but sufficient computational modules for adequate simulation of ship dynamics are selected in the distributed computing environment. In the future, they are integrated. It is possible on the basis of the concept of a virtual personal supercomputer.
В докладе будут рассмотрены следующие вопросы:
1. Ключевые технологические тренды HPC
2. Тенденции в области развития платформ для HPC, AI/ML, Big Data, классических ЦОД
3. Альтернативная энергоэффективная платформа для HPC, AI/ML, Big Data
4. Универсальный модульный сервер «М1»
5. Варианты исполнения сервера «М1»
6. Применимость «М1» в HPC, AI/ML, Big Data, классических ЦОД
7. Сравнение производительности в задачах HPC, AI/ML, Big Data
-
-
Modern physics experiments on particle collisions cannot operate without sophisticated software used at all stages of the work, including the design of the setup, control of the operation of different subsystems, data collection, online and offline processing and final physics analysis. This also holds true for the fixed target experiment, BM@N, the first experiment operating and taking data at the NICA complex in JINR. Since 2015, eight BM@N Runs, including the latest, physics one, have been conducted, and Run 9 with xenon ion beams is scheduled in the coming months. The report presents a set of software systems and services developed to automate BM@N data processing and storing on distributed hardware platforms, and some manual operated procedures during Run 9 of the experiment. Computing software as well as a complex of information systems providing information necessary for event data processing will be discussed. Both newly implemented software of the experiment and proven solutions used in recent BM@N Runs but constantly evolving will be demonstrated. Furthermore, a set of additional, but essential services will be noted, for instance, event daily (and integral) statistics service, which collects and visualizes event distributions divided into days by various parameters.
The Multi-Purpose Detector (MPD) is one of the three experiments of the Nuclotron Ion Collider-fAcility (NICA) complex, which is currently under construction at the Joint Institute for Nuclear Research in Dubna. With collisions of heavy ions in the collider mode, the MPD will cover the energy range 4-11 GeV to scan the high baryon-density region of the QCD phase
diagram. With expected statistics of 50-100 million events collected during the first run, MPD will be able to study a number of observables, including measurements of light hadrons and hypernuclei production, particle flow, correlations and fluctuations.
We will present selected results of the full-scale simulation of the MPD-NICA experimental setup for and discuss the data analysis techniques.
The Spin Physics Detector (SPD) collaboration is developing a universal detector to be installed at the second interaction point of the Nuclotron-based Ion Collider fAcility (NICA). Along with establishment of facility, refinement of the physical research program, growing up needs in data processing. To address these needs and provide essential IT services, the SPD Software & Computing (S&C) project was launched.
Key Objectives of the Project:
- Develop reliable, efficient, and maintainable software for experimental data processing.
- Establish a sustainable data processing system for both online and offline operations.
- Ensure robust and efficient storage of experimental data.
- Implement SPD-specific information systems and services.
This presentation outlines the general structure of the SPD S&C project and highlights the key IT challenges being addressed for the SPD experiment.
The Jiangmen Underground Neutrino Observatory (JUNO) is an international neutrino experiment and the determination of the neutrino mass hierarchy is its primary physics goal. JUNO established distributed computing system to organize resources for JUNO data processing activities. JUNO is in the commissioning phase now and plans to take data on July, 2025 with 3PB raw data each year. PBs of massive MC data has been generated among JUNO data centers through this system. More than 1PB commissioning data has been transferred successfully to remote data centers in time. The paper will give an overview of the system and describe the preparations for the coming data-taking.
The Institute of High Energy Physics (IHEP), Chinese Academy of Sciences (CAS), employs distributed computing systems to coordinate computing and storage resources across multiple international collaborations. Among these, the Jiangmen Underground Neutrino Observatory (JUNO) is a multipurpose neutrino experiment scheduled to begin official data acquisition in the second half of 2025. The JUNO distributed computing system, based on DIRAC, will handle the annual distribution of 2.4 PB of raw data and 0.6 PB of processed data, with tasks distributed across computing and storage facilities at IHEP, JINR, MSU, CNAF, IN2P3, and other partner institutions. Additionally, the High Energy cosmic-Radiation Detection (HERD) experiment, an upcoming space astronomy and particle astrophysics mission, is set to launch aboard China’s space station in 2027. HERD will also adopt a distributed computing architecture, using Rucio and DIRAC to generate and distribute approximately 90 PB of data over its 10-year mission. Data processing will be shared between Chinese and European computing sites. This report presents the research and applications of distributed computing systems in JUNO, HERD, and potential future IHEP-supported experiments. Key topics include distributed computing frameworks, grid middleware, and customized production services developed to meet experimental requirements.
-
В докладе представлен обзор систем мониторинга различных компонент Гетерогенной платформы HybriLIT. Сформулированы цели и назначение применяемых систем, являющихся одним из важных инструментов системного администрирования платформы.
Для контроля за состоянием вычислительных ресурсов применяется разработанная ранее система мониторинга, которая позволяет в реальном времени отслеживать загрузку CPU и GPU компонентов вычислительного узла, использование оперативной памяти и систем хранения данных, объём сетевого трафика и т.п.
В докладе представлена новая система мониторинга, являющаяся логическим развитием разработанной ранее системы, обеспечивающая ряд дополнительных функций для контроля за состоянием вычислительных ресурсов платформы.
В докладе рассматривается разработка системы аккаунтинга и обработки статистики использования вычислительных ресурсов суперкомпьютера «Говорун». Основное внимание уделено методам обработки и визуализации статистических данных, позволяющим оценивать эффективность использования вычислительных ресурсов и определять дальнейшие задачи по администрированию для оптимизации работы пользователей на суперкомпьютере.
Для решения задачи в качестве одного из компонентов системы была использована платформа Yandex DataLens — система бизнес-аналитики с открытым исходным кодом. Разработанная система формирует и визуализирует заранее подготовленные статистические данные по использованию вычислительных ресурсов в виде круговых диаграмм и сводных таблиц.
В докладе представлены структура системы, функциональные возможности и примеры практического применения. Система позволяет оценивать вклад различных групп пользователей в процентном отношении по ключевым метрикам, таким как количество счётных задач и общее количество затраченных ядро-часов.
В докладе будет представлено описание структуры и характеристик экосистемы ML/DL/HPC, построенной на базе многопользовательской среды разработки JupyterLab. Приведен обзор используемых технологических решений и решаемых задач.
Первая задача: инструментарий для публикации файлов Jupyter Notebook в формате электронных публикаций Jupyter Book для задач моделирования гибридных наноструктур сверхпроводник/магнетик (совместный проект ЛИТ и ЛТФ). Подготовленные материалы позволяют проводить учебные курсы и мастер-классы для пользователей, сотрудников ОИЯИ и студентов.
Вторая задача: сервисы для анализа траекторий мелких лабораторных животных в поведенческом тесте «Водный лабиринт Морииса» и веб-сервис для детекции и анализа радиационно-индуцированных фокусов (в рамках совместного проекта ЛИТ и ЛРБ).
Третья задача: полигон для квантовых вычислений, на котором установлен ряд квантовых симуляторов, в том числе для работы с квантовыми нейронными сетями.
В рамках совместного проекта ЛИТ и ЛТФ ОИЯИ развивается инструментарий для исследования систем, основанных на джозефсоновских переходах на базе Jupyter с использованием Python-библиотек. Разработанные алгоритмы размещаются в Jupyter Book, который дает возможность также добавлять реализованные модели, следить за всеми этапами математического моделирования и реализация вычислительных схем. Отметим, что ряд задач требует проведения многочисленных ресурсоемких расчетов, что приводит к необходимости существенного ускорения вычислительных схем, реализованных на Python.
В докладе представлены результаты сравнительного анализа параллельных вычислений проводимых на CPU и GPU с использованием библиотеки Numba JIT-компилятор (Just-In-Time) для языка программирования Python, на примере моделирования физических характеристик сверхпроводникового квантового интерферометра с двумя джозефсоновскими переходами (superconducting quantum interference device ¬– SQUID, СКВИД).
Вычисления проводятся на базе экосистемы ML/DL/HPC Гетерогенной платформы HybriLIT (ЛИТ ОИЯИ). Работа выполнена при поддержки РНФ в рамках проекта № 22-71-10022.
Ключевые слова: Python, математическое моделирование, джозефсоновские переходы, параллельные вычисления.
The network storage systems are treated, organized into several groups of devices with data redundancy capability.
We consider two schemes for managing data reconstruction process, namely the
declustered Redundant Array of Independent Disks (RAID) technique and, more generally, the Reed-Solomon (RS) error correction
coding within the framework of the Welch-Berlekamp algorithm.
These approaches essentially exploit the properties of circulant or Hankel matrices.
The reconstruction of all the units in the failed device causes a certain read/write load onto the survived devices. One of the major requirements to the storage device array is to manage the chunk group distribution across devices to produce a balanced read/write load on survived devices regardless of the location of the failed device. Construction of the data layout
with the aid of an appropriate circulant matrix provides one with such an opportunity. This surprisingly relates to the classical Graph Coloring problem.
For the problem of the error locator polynomial construction in the RS-coding, we propose an effective algorithm for recursive computation of the potential candidates in the form of Hankel polynomials.
Particle-in-cell (PIC) numerical simulations are widely used for the numerical modeling of plasma physics problems. These simulations are used primarily, but not exclusively, to study the kinetic behavior of the particles. For example, we used this method for numerical simulations of physics in linear particle accelerators [1,2].
The main idea of the method is to describe the plasma as a set of electrons and ions, which are modeled as discrete entities that move in continuous fields that are calculated on a computational mesh. The calculation of the motion of each particle is defined by electromagnetic fields. In our case, we use our modification of the finite-difference time-domain (FDTD) method as a discretization technique. A de-tailed description of the numerical method and scheme parallelization can be found in 3.
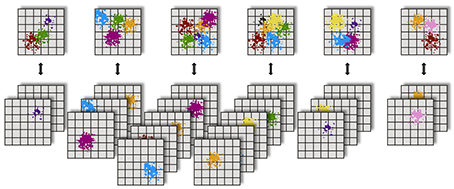
Figure 1 and 2 are briefly shows particle-domain decomposition and block-scheme of the algorithm for a one-time step. In our code, we apply a hybrid decomposition, divid-ing the computational domain along the z-axis into subdomains and assigning a group of processes to each subdomain. Within each group, particles are distributed almost uniformly: this uniformity is ensured by the even distribution of particles at the start, during the injection, and the exchanges by approximately equal quantities of particles with random processes of neighboring groups. A master processor of each group provides 3D arrays of the electromagnetic fields to his group and then gathers 3D arrays of the densities and mean velocities. During the Eulerian stage, the computations and the corresponding data exchanges with the ghost node values be-tween neighbor processes are performed only by the master group processes.
2 Vectorization
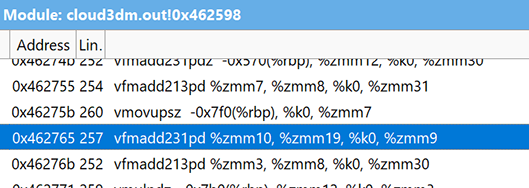
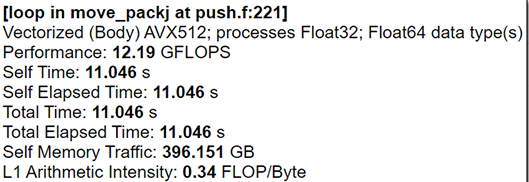
In our previous works 4, we used AVX512 intrinsics for numerical algorithm realization. However, the result of this approach is architecture-dependent code. At this moment, we are writing C++ or Fortran codes with different tricks that help the compiler build effective AVX512 code. In the case of our plasma physics solver, we have two of the “heaviest” functions which calculate particle data and density. For the autovectorization, we changed our mathematical expressions to ax+bx+c view. All division operations have been moved to separate operations. This approach helps the compiler to build FMA instructions using ZMM AVX-512 registers (see Fig.3 and Fig.4).

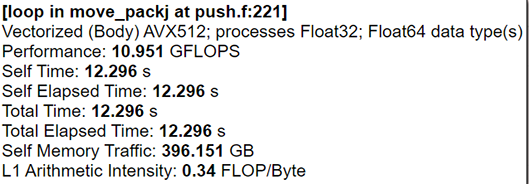
We also need to find data size parameters and particle pack size for better per-formance because of the specific particle-domain decomposition. Our tests showed that particle pack size can speed up particle data calculations function by up to 16% (see Fig.5 and Fig. 6) on the same data set.
Acknowledgments. This work was supported by the Russian Science Foundation (project 19-71-20026).
References
1. Chernykh, I., Kulikov, I., Vshivkov, V., Genrikh, E., Weins, D., Dudnikova, G., Cher-noshtanov, I., Boronina, M.: Energy Efficiency of a New Parallel PIC Code for Numeri-cal Simulation of Plasma Dynamics in Open Trap. Mathematics, 10, 3684 (2022).
2. Chernoshtanov, I.S., Chernykh, I.G., Dudnikova, G.I., Boronina M.A., Liseykina, T.V., Vshivkov, V.A. Effects observed in numerical simulation of high-beta plasma with hot ions in an axisymmetric mirror machine. Journal of Plasma Physics, 90, 2, 905900211 (2024).
3. Boronina, M.A., Chernoshtanov, I.S., Chernykh, I.G. et al: Three-Dimensional Model for Numerical Simulation of Beam-Plasma Dynamics in Open Magnetic Trap. Loba-chevskii J Math 45, 1–11. doi:10.1134/S1995080224010074 (2024)
4. Glinsky B., Kulikov I., Chernykh I., Weins D., Snytnikov A., Nenashev V., Andreev A., Egunov V., Kharkov E. The Co-design of Astrophysical Code for Massively Parallel Supercomputers. Lecture Notes in Computer Science, 10049, pp.342-353. DOI: 10.1007/978-3-319-49956-7_27 (2016)
A parallel numerical model for studying the generation of intense terahertz radiation in the interaction of bichromatic infrared laser pulses with a neutral gas and the results of simulations performed on its basis are presented. A fully kinetic model consisting of the Vlasov equations for the plasma distribution functions and Maxwell equations for the self-consistent electromagnetic field is used to simulate the macroscopic response of the plasma generated during ionization of a gas target by a laser field. Field ionization is taken into account within the framework of the cascade mechanism [1]. The numerical code is based on the Particle-in-Cell method and uses a finite difference time domain scheme (FDTD) for electromagnetic fields [2], a Boris pusher to update the positions and velocities of particles, and a charge conservation method [3] to fulfill Gauss's law for the electric field. The energy losses associated with ionization are accounted for by introducing an ionization current. Parallelization is achieved by domain decomposition. The distribution of numerical data between processing units and mutual exchanges are handled by MPI subroutines.
The work was supported by Russian Science Foundation within grant No. 24-21-00037. Numerical simulations were performed at the Joint Supercomputer Center of the Russian Academy of Sciences and at the Siberian Supercomputer Center of the Siberian Branch of the Russian Academy of Sciences.
References
1. V.S. Popov, "Tunnel and multiphoton ionization of atoms and ions in a strong laser field (Keldysh theory)", Phys. Usp. 47, N. 9, 855-885 (2004)
2. A. Taflove, S. C. Hagness, "Computational Electrodynamics: The Finite-Difference Time-Domain Method", 2nd ed. (2000), Chap. 5.8
3. T. Zh. Esirkepov, "Exact charge conservation scheme for Particle-in-Cell simulation with an arbitrary form-factor", Comp. Phys. Comm. 135 (2), 144–153 (2001).
На ресурсах экосистемы ML/DL/HPC Гетерогенной платформы HybriLIT разворачивается полигон для визуализации данных компьютерной томографии головного мозга. Полигон позволит строить изображения 3D объектов с использованием программных обеспечений для обработки, анализа и визуализации человеческого мозга. В дальнейшей перспективе полигон позволит внедрить новый математический аппарат улучшения качества полученных данных.
One of the key elements we must verify before joining a Grid infrastructure is network connectivity. A high bandwidth is required to move a large volume of data, and this must be accompanied by optimized routing.
Based on our previous experience with the Grid in ALICE (WLCG), AUGER (EGI), and EELA (Europe-Latin America), optimizing the path is challenging when Grid resources are distributed across several countries, and the National Research and Education Networks (NRENs) must adjust the routes accordingly.
For NICA, we have the support of CUDI (the Mexican NREN). We are working with them to resolve asymmetric routing and enhance connectivity to JINR. Additionally, with the support of CENIC in California, USA, we plan to explore connectivity to JINR through the Pacific Wave link.
Finally, with the added network traffic from several international collaborations and the hardware upgrade between CUDI and CENIC, we
anticipate a network bandwidth upgrade for UNAM shortly.
Athena is the ATLAS software framework that manages nearly all ATLAS production workflows. Most of these workflows rely on accessing data in the conditions database. CREST is a new conditions database project designed for production use in Run 4. Its primary goals are to evolve the data storage architecture, optimize access to conditions data, and enhance caching capabilities within the ATLAS distributed computing infrastructure. During the development of the CREST prototype, a new tool for interacting with the conditions database was integrated into Athena. Initially, this tool was based on the existing COOL implementation, enabling rapid testing of the new database in production workflows. However, due to maintenance challenges and the tool’s limited accommodation of CREST-specific features, a decision was made to redesign it. This article describes the new design for accessing CREST data from Athena. The redesigned toolkit simplifies maintenance, consolidates numerous metadata handling methods into a single class, and introduces a class for serializing and deserializing CREST data. This approach supports flexible handling of various data storage formats in CREST.
The SPD (Spin Physics Detector) facility at the NICA accelerator complex at JINR is under construction. In addition to the physics facility itself, the software for the future experiment is also being developed. There is already a constant demand for sufficiently large-scale data productions to simulate physical processes in a future experiment. To facilitate their implementation, MLIT staff are developing a set of systems and services that allow for the orderly storage and processing of experimental data both on JINR resources and on the resources of the institutes that are members of the SPD collaboration and, in common, forming a distributed computing environment of the experiment. The distributed computing environment is in trial operation, but it is already running full fledged productions based on requests from physics groups. Over the past six months, the system has modeled more than 1 billion physical events and generated more than 200 TB of data. An overview of the recent developments in the SPD offline software is presented in this talk.
Active work continues on the creation of the SPD (Spin Physics Detector) facility at the NICA accelerator complex, which is located at the Joint Institute for Nuclear Research (JINR). Since the facility will collect a large amount of data, data processing and storage will be carried out in a distributed computing environment. In this regard, there is a need for specialized software for effective data management.
At the current stage of research, significant amounts of data have already been accumulated, and the Rucio system is used as a management tool, a standard solution for data management in the field of high energy physics. The report will present the experience of putting Rucio into operation for the SPD experiment. Integration with other services, development of additional utilities, automation of work processes and development of internal monitoring will also be considered.
The Spin Physics Detector is a universal detector to be installed in the second interaction point of the NICA collider to study the spin structure of the proton and deuteron. Each large HEP experiment needs it's own applied software for handling generation, simulation, reconstruction and physics analysis tasks. Due to the commonality of such tasks among different experiments dedicated libraries and frameworks were developed. Gaudi is one of such physics frameworks which proved it's reliability and convenience by being used by many collaborations. Sampo is a Gaudi-based program platform which is now under development to serve the needs of SPD collaboration. Sampo is tended to replace the current SPD applied software SpdRoot.
В рамках доклада предложено решение на основе распределенной параллельной файловой системы Lustre для быстрого копирования данных и выполнения расчётов на СК Говорун и вычислительном кластере NCX, включающее режим отказоустойчивости на основе компонент Lustre и программных пакетов Pacemaker/Corosync. Разработанная архитектура построена на основе современного серверного оборудования с высокоскоростным подключением к сети, и имеющее географическое размещение в разных зданиях института. Приведены результаты тестирования производительности распределённой параллельной файловой системы Lustre, полученные на основе работы программной утилиты IOR, работающей на основе технологии MPI, а также работы счётных задач пользователей.
The SPD experiment will have to collect large amount of data: up to trillion events (records of a collision results) will have to be stored and analyzed, producing around ten petabytes yearly. A similar amount of simulated particle collisions for use in detector data analysis will be produced. This information will be distributed between a number of computing sites on a various storage locations, with duplication to avoid data loss and improve performance. The processing of the experimental data requires a wide variety of auxiliary information from many systems. To effectively access and handle all this data, as well as to operate detector itself, a number of information systems (IS) have to be created. A catalog of hardware components that SPD detector (Hardware database) is being developed, to provide information necessary in detector maintenance, data acquisition and processing. To support ongoing production of simulated data, a number of registries will be developed, including production registry, software version registry, geometry and magnetic field map registries. A catalog of hardware components that SPD detector (Hardware database) is being developed, to provide information necessary in detector maintenance, data acquisition and processing. With the development of the software framework and data model a catalog of the SPD physics events (Event Index) will be created to help to search and acess event data in the distributed storage system.
The Data Management System (DMS) design for BM@N, a fixed target experiment of the NICA (Nuclotron-based Ion Collider fAcility) is presented in this article. The BM@N DMS is based on the DIRAC Grid Community. This system provides all the necessary tools for secure access to the experiment data. The key service of the system is the File catalog, presenting all the distributed storage elements as a single entity for the users with transparent access. The file catalog also includes a metadata catalog, it can be used for an efficient search of the data necessary for a particular analysis. Access is provided via a REST API and a C++ interface, with authentication via BM@N SSO. The REST API helps to integrate the DMS with other software systems of the experiment, while the C++ interface allow BmnRoot to conveniently select events for a particular physics analysis.
The SPD experiment at the NICA collider involves not only the processing of multiple petabytes of data per year obtained from the detector, but also the production of similar amounts of data as part of the modeling of physical processes and expected signals from the front-end electronics. Because of this, the SPD experiment relies heavily on distributed computing for offline data storage and processing. In this talk we present preliminary steps to build a distributed computing infrastructure for the SPD experiment, including the network backbone, storage and computing facilities at participating parties, their software components and configuration along with some higher-level software components necessary for the smooth operation of such infrastructure.
Status of the INP BSU grid site presented. The experience of operation, efficience, flexibility of the cloud based structure is discussed.
Managing a complex Linux-based production environment of the computing center is a highly challenging operational task. Such tasks require a high level of automation in distributed multi-component systems, which must be applied to complex operational workflows. There are several approaches to achieve this goal, including: creating operational scripts based on Linux shell commands and programming languages, using specialized software for specific tasks (backups, configuration, management) or employing advanced orchestration tools. Among these solutions, the StackStorm automation engine stands out. This paper describes the use of this platform for orchestrating operational workflows such as distributed backups, distributed system upgrades and distributed system administration in the Linux-based computing center at NRC «Kurchatov Institute» – IHEP.
Computer administration of complex computing systems and distributed computing clusters presents significant challenges. Each sophisticated computer system has unique architecture and software configurations, it is custom-built and it is optimized for specific operational requirements and support conditions. Long-term system administration of such environments includes daily execution of various server commands - both for troubleshooting and for monitoring system behavior under different operational loads. These accumulated commands can be transformed into a valuable knowledge base for future use. This paper describes the development of such knowledge management system using Linux history tools at NRC “Kurchatov Institute” – IHEP
The Jiangmen Underground Neutrino Observatory (JUNO) is a major international neutrino experiment located in Kaiping City, Guangdong Province, southern China. To support its large-scale data processing needs, JUNO has adopted a distributed computing model based on the Worldwide LHC Computing Grid (WLCG) architecture. The JUNO distributed computing infrastructure includes collaborative sites from China, Italy, France, and Russia.
To ensure the stability, efficiency, and accountability of this international computing network, we have developed a monitoring system tailored for JUNO’s distributed computing environment. This system is designed to continuously track the operational status of computing sites and core services, as well as to account for cumulative resource usage across all participating centers. Leveraging a dedicated workflow management tool, it executes site-level Service Availability Monitoring (SAM) tests and aggregates diagnostic and performance metrics.
Currently, the system provides real-time data collection and interactive visualization capabilities across several critical areas, including site availability and reliability, data transfer performance, computing and storage resource statistics, and the status of essential grid and cloud services. This monitoring framework provides essential support for the daily operation and performance analysis of JUNO’s distributed computing system.
TBA
Federated data analysis is a technology for building distributed data analysis systems where no data is moved from their storage (collection) locations for analysis. This is a data analysis technology that defines a new level of access and transfers analysis and calculations directly to where the data is located. The World Economic Forum notes that, in fact, 97% of collected healthcare data is unused – it cannot be directly downloaded (uploaded to external sites), and there are no tools for federated analysis. The vast amount of data produced by healthcare institutions around the world remains underutilized. The state of affairs with research data is likely even worse. Federated data analysis allows researchers to safely analyze data from different organizations. Restrictions on data access, cybersecurity requirements, and the development of edge device intelligence are all factors that will ensure growing interest in this technology. The paper examines issues of designing the architecture of such systems.
This study addresses traffic load balancing (TLB) problem in Computing Centric Network (CCN) – an open, software-defined virtualized infrastructure that integrates distributed computing with high-speed data networks (DTN). Distributed TLB methods based on Multi-agent reinforcement learning (MARL) are quite perspective due to faster decision making and its adaptability to dynamic network traffic fluctuations. Despite the existing approaches such as Multi-agent routing using Hashing method (MAROH) showed better results than traditional approaches like ECMP and UCMP, and comparable results to centralized method, there are still too many inter-agent communications that slow down decision making and degrade channel bandwidth utilization efficiency.
Our key contribution is a two-layer MARL control plane, where agents may act based on its previous experience, stored in local memory, or communicate to make coordinated action. The proposed approach was implemented as an enhancement for MAROH. Experiment results showed that this approach reduces inter-agent communications by 80% while improving the objective function (sum of deviations from average link utilization) by 30%.
SHiP (Search for Hidden Particles) is a new general-purpose experiment at the SPS ring at CERN, aimed at searching for hidden particles proposed by numerous theories beyond the Standard
Model. An important element of the experiment is muon shield. On one hand, it must provide good background suppression, and on the other hand, it should not be too heavy. The Muon shield configurations was obtained using Bayesian optimization with several types of surrogates. This allowed for effective global multidimensional optimization in a 42-dimensional space and reduced the muon flux by 2.5 times while maintaining the original mass of the shield. A large number of MC Geant simulation tasks were performed on the Yandex Cloud Kubernetis cluster. The paper presents our ideas and approaches that we used to reduce the amount of computation while keeping the accuracy at an acceptable level.
The momentum anisotropy of particles produced in heavy-ion collisions serves as a sensitive probe of the matter formed in the collision overlap region. While detector effects can significantly distort the measured values of this observable, techniques exist to correct for acceptance non-uniformities and non-flow correlations. Developing an experiment-independent framework for anisotropic flow measurements can greatly simplify the process of obtaining robust physical estimates. We present QnTools, a universal software package designed for analyzing flow and polarization of particles produced in collisions. We demonstrate its application in extracting directed flow in the BM@N experiment and evaluating the performance of the MPD experiment for anisotropic flow measurements.
Multi-Purpose Detector (MPD) is aimed at the extensive investigation of
the properties of dense QCD matter created in heavy ion collisions. The
forward tracking detector would extend available rapidity range from
$|y| < 1.2$ to $|y| < 2.5$, which is critical for the studies of various
observables that can be used to probe the properties of the produced
matter. The main challenges for the detector are the momentum resolution
limited by the radial distance available for the track curvature
measurement that is strongly reduced at high pseudorapidities, large
material budget in front of the detector and high occupancy expected in
central heavy ion collisions.
ACTS (A Common Tracking Software) is extensively used for the forward
detector design developments. It provides a set of
experiment-independent tools for particle track reconstruction,
implemented with modern software concepts. The set includes the Kalman
filter for track fitting, seeding tools and combinatorial Kalman filter
for track finding. Coupled with an independent geometry description,
these algorithms can be adapted to various detector types.
Performance of ACTS-based implementation of track reconstruction was
tested both in simplified and realistic environments in terms of event
multiplicity. In this report, we will discuss the results of the forward
tracker performance studies.
Particle identification (PID) is an essential step in the data analysis workflow of high-energy physics experiments. Machine learning approaches have become widely used in high-energy physics problems in general, and in PID in particular for the last ten years. Due to the fact that conventional algorithms of PID have poor performance in the high momentum range. However, due to the absence of ground-truth labels in experimental data, classifiers must be trained on Monte Carlo (MC) simulations. This creates a fundamental challenge: differences between the simulated and real data distributions known as data shift. It can significantly affect model generalization and performance. The impact of data shift was explored by comparing particle classification results across several MC datasets generated with different simulation settings. How the distributions of key features (momentum, energy, velocity, mass squared) vary between simulations was analyzed. The results highlight the need to carefully validate and adapt machine learning models to ensure reliable performance on data with potentially shifted distributions, especially in scenarios where real labels are unavailable.
This work shows the application of logistic regression model for particle identification task in Multi Purpose Detector (MPD) experiment on Nuclotron based Ion Collider fAcility (NICA) at Joint Institute for Nuclear Research. The model has been tried on Monte-Carlo dataset provided by MPDRoot software package and compared against n-sigma method, included in MPDRoot, and XGBoost gradient boosted decision tree method, previously investigated. Feature importance analysis was conducted to explore the possibility to decrease model size and increase computational speed.
Modeling the dynamics of a dissipative system of interacting fuel elements of the new-generation NEPTUN pulse reactor is considered from the standpoint of Hamiltonian formalism. An exact analytical expression is obtained within the “zero” approximation, it describes the evolution of the phase portraits of the system and allows for an efficient numerical implementation on the architecture of GPU graphics processors.
The algorithm enables to find natural frequencies and oscillation modes, as well as to optimize system parameters to assess the stability of the reactor operation.
The triple GEM detector is one of the basic components of the hybrid tracking system in the BM@N experiment. It consists of gas chambers located along the beam axis, designed to register particles passing through matter in the form of responses on a microstrip readout plane. The presented work describes the features of detector response simulation and considers a method for this simulation using Generative-Adversarial Networks (GAN). A comparative analysis is provided between the proposed generative model and a previously developed parametric signal generation method. Particular attention is paid to data preparation for network training, as well as the formation of feature vectors for Conditional GAN (C-GAN).
Задачами компьютерной науки являются разработка, анализ, применение и оценка различных характеристик алгоритмов, используемых для решения специализированных задач. При этом немаловажную роль в прикладных исследованиях играет стратегия формирования модели предметной области, в рамках которой будут проводиться ассоциации между исследуемыми понятиями, объектами и программными абстракциями [1].
Особенностью представленного в работе подхода является применение мультипарадигменных абстракций с развитой семантикой для разработки программ синтеза элементов микро-оптики с возможностью параллельных вычислений. Реализованные на языке С#, модели расчета элементов микро-оптики объединяют в себе процедурную, объектно-ориентированную и обобщенную парадигмы программирования, что позволяет, с помощью параметрического полиморфизма подтипов, специфицировать требования к аргументам алгоритмов в виде базовых абстракций с дальнейшей возможностью их применения к множеству типов данных.
Алгоритм решения обратной задачи дифракции на некоторой области оптического элемента структурно можно разделить на три этапа: чтение данных (обход входных диапазонов), операция расчёта требуемой фазовой функции в конкретной точке и запись полученного значения в результирующую структуру данных или систему хранения. Использование мультипарадигменного анализа позволило сформулировать критерии общности и изменчивости [2], специфичные для каждого этапа, в терминах которых были определены варианты поведения алгоритма.
На примере нескольких видов оптических элементов (дифракционная сферическая линза, дифракционная цилиндрическая линза, радиально-симметричный аксикон, киноформный аксикон, голографический аксикон) выполнено исследование возможности создания универсального обобщенного алгоритма синтеза микрорельефа с применением мультипарадигменного подхода. Проведена проверка возможности применения распараллеливания расчёта, во время которой для каждого типа элемента использовалась параллельная версия обобщенного алгоритма [3]. Разработанная программная архитектура позволила без осложнений ввести режим распараллеливания расчёта, что обеспечило многократное ускорение при увеличении апертуры элементов без потери качества итоговых изображений.
SUMMARY
Using several types of optical elements (diffractive spherical lens, diffractive cylindrical lens, radially symmetric axicon, kinoform axicon, holographic axicon) as an example, a study was conducted to determine the possibility of creating a universal generic algorithm for microrelief synthesis using a multi-paradigm approach. Testing was conducted to determine the possibility of using parallel calculation, during which a parallel version of the generic algorithm was used for each type of element [3]. The software architecture made it possible to implement a parallel computing mode without complications, with multiple acceleration when increasing the aperture of elements without loss of quality of the final images.
[1] Evans, E. Domain-Driven Design: Tackling Complexity in the Heart of Software – Addison-Wesley Longman Publishing Co., Inc., 2004.
[2] Coplien, J., Hoffman, D., Weiss, D. Commonality and variability in software engineering // IEEE Software, V.15, N.6. - 1998, pp. 37-45.
[3] Yablokova L., Lee A., Yablokov D.E. etc. Using a Parallel Approach to Calculating Micro-Optics Elements in DOERIS // 2024 10th International Conference on Information Technology and Nanotechnology, ITNT 2024. — 2024.
The problem of supercomputer modeling of the processes of creating metallic composite materials from nanomaterial nanoclusters is considered. The general relevance of the research is related to the development of technology for manufacturing nanoscale electronic components. The relevance of a specific study is related to the need to develop both mathematical and software tools for modeling all stages of manufacturing. In this paper, we analyze the final stage of the process, when individual metal clusters interact with each other and with the substrate. These processes are studied by classical molecular dynamics (MD) methods using parallel computing. The focus of the research is to develop an approach to calculating the interaction of different-material metal systems. The problem of interaction of copper and nickel nanoclusters in the manufacture of the corresponding composite is chosen as an example. Preliminary testing confirmed the effectiveness of the developed parallel computing procedure. The work was supported by the Russian Science Foundation, project No. 25-71-20016.
The needs of civil aviation and space research require a comprehensive study of the processes of flow around aircraft, including supersonic flow. In this area, along with empirical experimental studies, mathematical modeling methods are widely used. The classical structure of a computational experiment includes the stage of preparing the initial data, launching the computational application, and analyzing the results obtained. Often, such calculations require the use of supercomputer-level resources. Today, digital platforms are used to simplify the computational experiment. These systems allow performing the entire computational cycle through a unified graphical user interface available on the Internet. The general architecture and core of such a platform were developed by the group of authors earlier. The report proposes to consider one of the directions of the system development. It is related to the construction of the geometry of the streamlined object. The main feature in this case is the implementation of the interface component that allows the preparation of a 2D/3D computational domain and its marking using a web browser. The obtained geometric description allows us to conduct the computational experiment of supersonic flow around the composite object.
The work was supported by the Russian Science Foundation (project No. 25-11-00099, https://rscf.ru/project/25-11-00099/).
Charge transfer processes in biopolymers such as DNA are actively investigated using mathematical and computer modeling. A large number of works are devoted to studies of polaron mechanism of charge transfer. We have modeled the dynamics of Holstain polaron in a chain with small random perturbations and under the influence of a constant electric field.
In the semi-classical Holstein model the region of existence of polarons in the thermodynamic equilibrium state depends not only on the temperature but also on the chain length. Therefore when we compute the dynamics from the initial polaron data, the mean displacement of the charge mass center differs for different-length chains at the same temperature. For a large radius polaron, it is shown numerically that the “mean polaron displacement” (which takes account only of the polaron peak and its position) behaves similarly for different-length chains during the time when the polaron persists. A similar slope of the polaron displacement enables one to find the polaron mean velocity and, by analogy with the charge mobility, assess the “polaron mobility”.
For a temperature prescribed, we compute a set of realizations (dynamics of the system from different initial data and with different pseudo-random time-series) and then calculate trajectories averaged over realizations. This formulation allows for trivial parallelization (using MPI) “one realization – one node” with an efficiency of almost 100%.
To reduce the calculation time, parallelization was performed on a node containing multi-core processors when calculating a realization using shared memory and openMP. The dynamic equations for the n-th site of the chain explicitly include only its closest neighbors. Therefore, the chain is divided into short parts that are integrated at the step independently on different cores of the node, while only for the boundary sites the data calculated by other processes are required. All processes must go to the next iteration synchronously; the synchronization operation also takes time. The longer the chain, the smaller the ratio of exchanged data to calculated data, and the greater the gain from parallelization.
Test studies of the gain t1/tp were made (t1 denotes the execution time of the sequential variant, tp denotes the execution time of the task parallelized using openMP on p threads). Maximum t1/tp ~ 0.9 p allows to significantly reduce the machine time of a realization.
The calculations were performed on the supercomputers k-60 and k-100 installed in the Suреrсоmрutеr Сеntrе of Collective Usage of KIAM RAS
В работе исследуется применимость методов машинного обучения для
прогнозирования времени выполнения задач на узлах гетерогенной высокопроиз-
водительной вычислительной сети. Актуальность проблемы обусловлена необхо-
димостью эффективного использования вычислительных ресурсов и оптималь-
ного планирования задач. В качестве входных данных используется информация
о запусках задач, где известны лишь некоторые параметры программ и использу-
емые ресурсы.
Развитие современных вычислительных систем направлено на увеличение количества вычислителей и ускорителей, в том числе и разнородных: матричных ускорителей, MIMD, SIMD и др., что требует модернизации вычислительных алгоритмов с учетом структуры компьютера. В докладе рассматривается матричная модификация метода муравьиных колоний (ACO) для решения дискретной параметрической задачи, поиска дискретных значений параметров, обеспечивающих оптимальные значения критериев. Значения критериев при этом определяются в результате работы аналитических или имитационных моделей также запускаемых на вычислителе. Для решения параметрической задачи в методе ACO применяется графовая структура данных, в которой для каждого значения каждого параметра выделяется одна вершина, а муравей-агент должен выбрать по одному значению для каждого параметра. Данная структура позволяет рассматривать работу ACO в виде матричных операций и эффективно применять матричные, SIMT и SIMD ускорители. Предложенная матричная модификация, работающая с оптимизированной графовой структурой, позволяет достичь ускорения от 13 до 22 раз по сравнению с оригинальным методом при выполнении на CPU. Во многом такое ускорение обусловлено работой современного оптимизирующего компилятора C++. Предложен алгоритм представления матричного ACO для SIMD ускорителя и гетерогенного вычислителя. Проведены исследования на ускорителе с применением технологии NVIDIA CUDA, ускорение составило от 7 до 20 раз. Применение технологий AVX и OMP позволило обеспечить ускорение до 35 раз, по сравнению с классической реализацией ACO. Для применения ACO на GPU с применением технологии CUDA требуется пересмотр алгоритма, разделение данных по типам памяти, правильное разделение на потоки и блоки, решения проблем синхронизации и передачи данных между CPU и GPU. Предложен алгоритм для гетерогенного вычислителя, выполняющего матричные преобразования на CPU и вычисление пути муравья-агента на GPU, который показал ускорение от 30 до 70 раз. Исследования проводились на различных GPU персональных компьютеров и на высокопроизводительном кластере РЭУ. Проведено теоретическое исследование эффективности применения гетерогенного матричного ACO на гетерогенном вычислителе, состоящем из наборов MIMD ядер и SIMD ускорителей. Предложен подход к определению предела теоретического ускорения алгоритма и оптимальная структура гетерогенного реконфигурируемого вычислителя. Предложены рекомендации по выбору эффективного параллельного алгоритма ACO с учетом времени и принципов взаимодействия, топологии вычислителя и времени выполнения вычислений в модели в процессе определения значения целевой функции.
Солвер глобальной и дискретной оптимизации SCIP [1], scipopt.org, развивается с 2005 года и предназначен для решения задач математического программирования, в т.ч. с дискретными переменными, методом ветвей-и-границ-и-отсечений (branch-and-bound-and-cut). С конца 2022 года он свободно доступен в исходных кодах по лицензии Apache 2.0. Хотя по производительности SCIP уступает коммерческим солверам (Gurobi, COPT, CPLEX), он очень полезен в поисковых исследованиях поскольку применим для более широкого класса нелинейных задач, по сравнению с Gurobi и COPT. Типовой сценарий работы с солвером SCIP: подготовка формальной модели задачи и исходных данных для оправки их солверу, получение решения и анализ результатов. Как показала практика, одним из удобных вариантов является использование файлов в форматах стандарта AMPL, ampl.com: NL-файлов для исходной задачи и SOL-файлов для полученного решения. Для генерации NL-файлов и чтения результатов из SOL-файлов удобно применять свободно доступный пакет Pyomo, pyomo.org.
Производительность SCIP может быть существенно повышена за счет работы в параллельном режиме через библиотеку UG (ubiquity generator), ug.zib.de. Разработчики предлагают две параллельные реализации [2, 3]: многопоточный FiberSCIP, для многопроцессорных систем с общей памятью; ParaSCIP, для кластеров с коммуникацией по технологией MPI. К сожалению, эти параллельные солверы не имеют встроенной поддержки AMPL-форматов, что затрудняет их широкое применение.
В докладе описывается простой способ адаптации этих параллельных солверов к AMPL-форматам, где в роли «транслятора» форматов входных и выходных данных используется «обычный» солвер SCIP и несложный Bash-скрипт. В частности, это позволяет применять FiberSCIP и ParaSCIP непосредственно из Python-приложений на базе Pyomo или в сервисах оптимизационного моделирования на основе Everest, optmod.distcomp.org.
Работа выполнена в рамках государственного задания ИППИ РАН, утвержденного Минобрнауки России.
K. Bestuzheva, A. Gleixner, T. Koch, M.E. Pfetsch, Y. Shinano, S. Vigerske et al. The SCIP Optimization Suite 9.0 // Optimization Online, 2024, 36 pp. https://optimization-online.org/?p=25734
Yuji Shinano. ParaSCIP and FiberSCIP libraries to parallelize a customized SCIP solver. SCIP Workshop 2014, 30.09-2.10, 2014, Zuse Institute Berlin, https://www.scipopt.org/workshop2014/parascip_libraries.pdf
Y. Shinano et al. FiberSCIP - A Shared Memory Parallelization of SCIP // INFORMS Journal on Computing, 2018, 30(1), P. 11-30. https://doi.org/10.1287/ijoc.2017.0762
Параллелизм на уровне процессов является неотъемлемой частью расчетов на крупных вычислительных кластерах. Примером может служить моделирование процесса диффузии отдельных атомов по поверхности твердой фазы. Инструменты для полного сканирования поверхности потенциальной энергии дают исчерпывающую информацию об энергетических барьерах и путях диффузии, но вследствие больших вычислительных затрат редко входят в состав квантово-химических пакетов.
В данной работе предлагается решение этой задачи на примере моделирования диффузии атома водорода по поверхности меди в рамках исследований в области водородной энергетики. Алгоритм сканирования поверхности потенциальной энергии выполнен в виде Python-скрипта, который обеспечивает запуск, распараллеливание и контроль вычислений квантово-химических кодов. Расчеты формируются из пула точек, являющихся узлами решетки сканирования, и представляют собой индивидуальные задачи, связанные через общий набор файлов, что исключает накладные расходы на интенсивный обмен данными между процессами, позволяя минимизировать потери производительности и упростить постановку задачи в очередь выполнения высокопроизводительного кластера.
Работа является продолжением цикла исследований, проводимых в Суперкомпьютерном центре Воронежского госуниверситета, представленного ранее на GRID’2023
This work focuses on the development of a method for automating the processes of building, testing, and deploying application software for the distributed data processing system of the SPD experiment at the NICA collider. The study involves a systematic analysis of the existing development process, identifying key issues such as the high labor intensity of manual operations and the lack of a unified methodology.
Based on the analysis of modern practices and technologies, a comprehensive method has been developed, incorporating GitFlow, CI/CD tools, and containerization using Docker and Apptainer. The methodology automates the creation of virtual environments, building and testing software modules, as well as the publication and deployment of images to container registries.
The practical implementation of the methodology has been deployed in several projects within the SPD collaboration, leading to a reduction in preparation time for releasing new software versions, and improving the quality and reproducibility of software products. This work demonstrates a substantial improvement in development processes for scientific collaborations and can be adapted for other large-scale projects.
The report presents the design of the Data Quality Monitoring (DQM) system for the BM@N experiment of the NICA project, including a description of the system's objectives, a brief overview of such systems that operate in the CERN LHC experiments, and general approaches to creating the systems. The features of the BM@N experiment are analyzed, such as the rate and volume of data received during the setup operation, and other parameters that must be taken into account when designing the BM@N DQM system. The system architecture, object model, and database scheme are presented, and the structure of configuration files that will be used for fine-tuning the work of the system is described. The future user interface of the Data Quality Monitoring is also discussed.
In 2025, the 9th data-taking run is scheduled for the BM@N experiment. Since February 2023, when data from the 8th run were acquired, the BM@N data processing has been carried out using a geographically distributed heterogeneous infrastructure based on the DIRAC Interware software. For the 9th run, an automated task-launching methodology has been developed. The processing is triggered by the appearance of RAW-type files associated with the 9th run in the DIRAC file catalog. A dedicated service periodically checks the catalog for new files requiring processing and initiates the corresponding tasks. Since BM@N data processing occurs in two stages (first, RAW → DIGI format conversion, followed by DIGI → DST conversion), two task triggers must be defined: one for the arrival of RAW files and another for DIGI files. Automating the processing pipeline enables rapid feedback on the experimental data quality, allowing for timely Data Quality monitoring and issue resolution.
Operational experience with the Hyperloop train system is presented. This framework facilitates organized grid data analysis in ALICE at the Large Hadron Collider (LHC). Operational since LHC Run 3, the system enables efficient management of distributed computing resources via a web-based interface, optimizing workflow execution and resource utilization. Hyperloop structures analyses as modular trains composed of interconnected wagons – configurable workflows handling both user-defined tasks and expert-level services. Key features encompass automated resource estimation, testing, submission, alongside tools for version control and dataset comparison.
Based on multiple years of work as a Hyperloop operator, the role of such framework in running the organized grid-based analysis for large collaborations is highlighted, and its adaptability to other mega-science projects is discussed. Solutions for stability, validation, and user accessibility are highlighted. Furthermore, the application of this operational experience to the development of analysis train systems for the MPD experiment at the NICA collider is discussed.
Comment:
Hyperloop is a framework for the grid data analysis in ALICE. It is run 24/7 and operated by four groups by set by geographical considerations. In 2022-2024 I was chairing the team of operators from St. Petersburg State University. Member of ALICE Collaboration since 2011. In 2014-2015 Coordinator of mass Monte Carlo production in ALICE. 2021-2022 expert of PWG-CF working group of ALICE for Monte Carlo modelling. Since 2024 - responsible for grid infrastructure for LHC/NICA in St. Petersburg State University.
The visualization of experimental data plays a vital role in high-energy physics, enabling intuitive interpretation and analysis of particle collision events. Advancements in web technologies have significantly influenced the development of interactive 3D event displays, improving accessibility and performance. This article examines the implementation of modern tools such as React, Bun, Three.js, and JSRoot in the creation of a web-based event display for the MPD experiment at the NICA collider. These technologies optimize rendering efficiency, enhance data processing, and simplify integration within browser environments, eliminating dependencies on specialized software. The approach presented ensures seamless usability across multiple platforms while maintaining high visualization fidelity. Key principles of event data processing, geometry transformation, and interactive visualization techniques are outlined, demonstrating the impact of modern web development on scientific applications in high-energy physics.
Budker Institute of Nuclear Physiscs has several prospects on future experiments. Ranging from large complexes such as well known Super Charm-Tau (SCT) factory, or reсent project of the detector and VEPP-6 accelerator (there is no official name for the detector yet), to small setups for detector studies.
The project of the VEPP-6 is similar to Super Charm-Tau factory. It is a high-luminosity electron-positron collider, but it is planned to work at lower energies and dedicated for studies of strange and charmed hadrons.
The project implies single collision point equipped with a universal particle detector. The Aurora software framework, being developed for the SCT detector, now is in process of separation to framework and detector specific parts.
It is based on trusted and widely used in high energy physics software packages, such as Gaudi, Geant4, and ROOT. At the same time, new ideas and developments are employed, in particular the Aurora project uses DD4hep for geometry description and PODIO for data storage.
There will be presented next release of the Aurora framework, its core technologies, structure and roadmap for the near future.
Modern high-energy physics (HEP) experiments generate and store vast volumes of data, which users access through complex and irregular patterns. Efficient data management in such environments requires accurate forecasting of dataset popularity to optimize storage, caching, and data distribution strategies. In this work, we propose an approach for predicting future dataset access patterns using transformer-based deep learning models. By leveraging historical logs of user interactions with HEP datasets, our method captures temporal dependencies and contextual signals to forecast both short- and medium-term data demand.
We evaluate our approach on real HEP access logs and conduct a comparative analysis of the accuracy of the proposed transformer-based method with previously used methods, including Facebook Prophet, Random Forest, and LSTM. Our results suggest that transformer architectures are a powerful tool for proactive data management in large-scale scientific computing environments. Although the proposed method is demonstrated using user analysis data access patterns, it is equally applicable to production data popularity forecasting.
Additionally, we implement a custom evaluation metric focused on the total sum of future accesses compared to the sum of predicted accesses, rather than relying on traditional day-by-day accuracy metrics.
В 2016 году на факультете компьютерных наук Воронежского государственного университета был введён в эксплуатацию гибридный вычислительный кластер. Он отражал текущие тенденции в развитии суперкомпьютеров и был собран таким образом, чтобы наиболее полно представить имеющиеся архитектурные решения в области построения высокопроизводительных систем. Вычислительное поле состоит из десяти узлов. Семь из них включают в себя по два математических сопроцессора Intel Xeon Phi 7120P, а три других укомплектованы графическими сопроцессорами NVIDIA Tesla K80. Для взаимодействия используется интерконнект на базе Mellanox Infiniband ConnectX-3. Таким образом, кластер позволяет обучать студентов программированию с использованием архитектуры CUDA, включая расширения PyCUDA, а также технологиям OpenMP и MPI с использованием сопроцессоров Intel. Кроме того, на нём выполняются бакалаврские и магистерские выпускные квалификационные работы студентов факультета компьютерных наук, ведутся научные исследования в области вычислительной химии и физики.
Благодаря имеющимся архитектурным особенностям гибридный кластер хорошо подходит для обучения студентов навыкам администрирования современных суперкомпьютеров, таким как работа с очередью исполнения, построение системы хранения данных, обеспечение удалённого доступа и мониторинг его ресурсов. В связи с окончанием поддержки основной части оборудования появились сложности с сопровождением отдельных компонентов, что приводит к необходимости углубленно изучить их структуру. Однако, несмотря на сложности с администрированием, кластер продолжает выполнять все возложенные на него функции.
При решении задач эволюционным алгоритмом на грид-системах из персональных компьютеров возникает ряд специфических затруднений, снижающих эффективность и производительность.
Одной из причин снижения производительности является низкая стабильность отдельных узлов. Такие узлы скачивают вычислительное задание, но по ряду причин не возвращают результат за разумное время. Это приводит к задержкам генерации нового поколения на основе всех результатов предыдущего поколения. В предшествующих публикациях такая проблема получила название «семеро одного не ждут». В докладе будет предложен способ преодоления этой проблемы посредством поддержки стабильного ресурса, основанного на системе очередей.
Кроме этого важной причиной снижения эффективности является принципиальная невозможность предварительной оценки вычислительной сложности задания. Современные методы позволяют упаковывать несколько малых заданий в одно BOINC-задание для последовательного выполнения на вычислительном узле. Без предварительной оценки время выполнения некоторых составных заданий будет превышать разумные пределы. А при отсутствии механизма упаковывания отдельные задания будут выполняться чрезмерно быстро, что является неэффективным при высоких накладных расходах на инициализацию. В докладе будут предложены способы управления вычислительной сложностью BOINC-заданий, основанные на отслеживании времени на стороне вычислительного узла.
Предложенные методы были успешно внедрены в проект USPEX@HOME и в настоящее время активно используются для решения задач эволюционным алгоритмом.
Доклад посвящён некоторым аспектам сопровождения и управления современным вычислительным комплексом. В ходе выступления будут рассмотрены следующие темы:
Desktop grid systems can be used for a wide range of combinatorial tasks. Such tasks include, among others, the construction of spectra of Latin squares. The task can be divided into many autonomous subtasks that can be performed on various nodes of a desktop grid. One of the features of the problem of constructing Latin square spectra is the different computational complexity of the subtasks. However, the computational complexity of a particular subtask cannot be determined in advance. The load balancing subsystem handles the distribution of subtasks between nodes. The complexity of such a distribution lies in the fact that the nodes of a desktop grid have different computing power, and they can also periodically and unexpectedly shut down. The main tasks of the load balancing subsystem in such a desktop grid are to reduce the downtime of nodes and increase the probability of calculating a subtask before the node is turned off. The paper discusses modifications to the load balancing subsystem in a desktop grid based on the BOINC platform. It is proposed to use machine learning methods to estimate the complexity of subtasks and the probability of calculating a specific subtask at a specific node. The results of using a modified load balancing subsystem are presented using the example of solving the problem of constructing a spectrum of Latin squares for the number of transversals.
The improvement of the server load balancer in distributed computing systems based on the BOINC platform is being considered. Such a grid system includes an application server, a database, a task scheduler, and client software installed on the nodes. The efficient operation of the scheduler determines the use of computing resources and minimizes node downtime. Simulation modeling using the ComBoS simulator is used to analyze and modify scheduling algorithms, as well as reduce overhead costs. The use of ComBoS makes it possible to study in detail the behavior of a heterogeneous system in a controlled environment, avoiding the costs and limitations associated with the actual functioning of the grid system. As part of the work, computational experiments were conducted to simulate the scenarios of the grid system based on historical data from the RakeSearch project. During the simulation, the capacity of client resources varied, as well as the complexity of tasks. Analyzing the status of clients throughout the simulation allowed us to identify and minimize task waiting intervals, which led to an increase in the efficiency of using available computing power.
Distributed deep learning methods can be used to solve various image analysis and processing tasks. It is quite difficult to assemble a large dataset for a certain set of tasks due to restrictions on data distribution. For such tasks, federated learning is used. The main feature of this method is the presence of local data on the nodes of the distributed computing system, which cannot be transferred to other nodes due to various restrictions. The task of determining the coastline from satellite images is reduced to the task of segmentation. DeepResUnet and TransUnet deep neural network models were selected. Landsat8 with images of rivers and bays in Russia was chosen as the dataset. Computational experiments were conducted to train two models on one node (deep learning), on multiple nodes (distributed deep learning and federated learning). The results of solving the problem of determining the coastline both on a single node and on a distributed system are presented. For experiments on federated learning, various methods of data separation between nodes of a distributed system have been identified. Data separation between nodes is proposed, both according to the geographical location of the satellite image and randomly. A comparative analysis of the results of federated learning with various methods of data distribution is discussed.
-
-
Compressed representations of input data are used to solve many problems in the natural sciences, in particular in the field of cosmic rays. Conventionally, the input data are mapped to a low-dimensional vector, which is a set of physically motivated parameters. For example, for images of extensive air showers (EAS) recorded by Cherenkov telescopes, the so-called Hillas parameters are used, which are obtained from the statistical moments of two-dimensional images. The problem with this approach is that it is difficult to determine to what extent the used set of parameters contains enough information necessary for further study of the physical phenomenon.
The effective and popular ways to construct compressed representations are autoencoders (AEs). Using elements of the AE latent space as a vector representation of the input data has a number of advantages over the conventional approach. In particular, in this approach, the dimensionality of the vector representation in the latent space can be varied to achieve the required level of accuracy. The problem with this approach is that the vector representation of the data in the AE latent space cannot be interpreted directly, and therefore its control is also difficult.
In the presented work, an approach is proposed based on the training of two additional neural networks whose function, on the one hand, is to provide an interpretation of the latent space vector in terms of a physical problem, and on the other hand, to allow control of the representation vectors through available physics parameters. In general, the set of physics parameters into which the latent space is mapped and the set of physics parameters for the inverse mapping may differ. Their choice is determined by the problem being solved. This approach was tested on data obtained from the Cherenkov telescopes of the TAIGA experiment.
The work was carried out with financial support from the Russian Science Foundation, grant No. 24-11-00136
Studying the fluxes of gamma quanta (gamma rays) of various energies generated in the vicinity of galactic and metagalactic sources is one of the most promising ways to study the sources themselves, and hence the important processes occurring in the Universe. The fact is that charged cosmic rays (elementary particles and atomic nuclei) are significantly influenced by galactic and intergalactic magnetic fields, which leads to a strong distortion of their trajectories and, as a result, to the loss of any information about the place of their origin. Gamma-ray astronomy does not have these shortcomings, since photons trajectories are not distorted because of their electric neutrality and therefore indicate the direction of their origin. In many ways, these reasons have contributed in recent years to the rapid development of experimental gamma-ray astronomy in the world, see, e.g., [1,2] and references therein.
An important fact that must be taken into account is that the flux of gamma rays is very small compared to the flux of cosmic rays (electrically charged particles), the ratio is not higher than 1:1000. Because of the large background its is crucial that the methods for classification of the recorded events perform well. For this aim new algorithms are explored to enhance the separation of gamma rays and charged cosmic rays including those based on deep learning [2]. In this work we suggest a new method for detecting rare gamma quanta against the background by heavily using normalizing flow-based deep learning models. The latter are generative models that explicitly models a probability distribution by leveraging normalizing flow, which is a statistical method using the change-of-variable law of probabilities to transform a simple distribution into a complex one (see, e.g., [3] and refs therein). We consider various versions of the method based both on one-class and two-class learning (classification). Moreover in the former case there exist the possibilities to choose as the training class both gamma quanta and the charged particles. The method is intended to be applied for processing the experimental data of the TAIGA (Tunka Advanced Instrument for Gamma Astronomy and Cosmic-Ray Physics) project [4].
The work was carried out with financial support from the Russian Science Foundation, grant No. 24-11-00136
References
[1] Sitarek, Julian. "TeV instrumentation: current and future.Galaxies 10, no. 1 (2022) 21.
[2] Demichev, Andrey, and Alexandr Kryukov. "Using deep learning methods for IACT data analysis in gamma-ray astronomy: A review."Astronomy and Computing 46 (2024) 100793.
[3] Kobyzev, Ivan, Simon JD Prince, and Marcus A. Brubaker. "Normalizing flows: An introduction and review of current methods."IEEE transactions on pattern analysis and machine intelligence 43, no. 11 (2020) 3964-3979.
[4] N. Budnev et al., "TAIGA—A hybrid array for high-energy gamma astronomy and cosmic-ray physics", Nuclear Instruments and Methods in Physics Research, A958 (2020) 162113
The FITTER_WEB application is designed to solve the problem of fitting experimental data obtained in various physical experiments, and is deployed in the JINR cloud infrastructure. It uses the computing power of the ROOT package and provides a web interface for fitting data with theoretical models based on the resolution function. However, creating custom models required writing code manually, which could be difficult for some researchers.
This paper presents an extension of the functionality of this web application through integration with the DeepSeek artificial intelligence model. This allows you to automate the process of creating filtering functions in C++, which is especially useful for users who do not have deep programming knowledge.
Для оптимизации процесса исследования микрофотографий поверхности монокристалла Nd2Fe14B при наличии внешнего магнитного поля был разработан комплекс программ для распознавания таблиц и цифровых значений, получаемых после обработки исходных изображений программой Gwyddion. Основная сложность предварительной обработки исходных данных заключается в том, что Gwyddion выдает результаты вычислений в виде цифрового изображения. Для обхода этого ограничения, оптимизации предварительной обработки данных и расчета фрактальных параметров был разработан комплекс программ, преобразующий растровое изображение в графики и числовые таблицы фрактальных параметров.
Для решения поставленной задачи распознавания предлагается использовать библиотеку Python-tesseract – инструмент оптического распознавания символов (OCR) для Python, который представляет собой оболочку для Google’s Tesseract-OCR Engine. Он также полезен как автономный скрипт вызова для tesseract, поскольку он может читать все типы изображений, включая jpeg, png, gif, bmp, tiff и другие.
В качестве объекта исследования в данной работе использована полученная ранее методом магнитооптического эффекта Керра серия из 28 микрофотографий ДС на базисной плоскости монокристалла Nd2Fe14B в виде диска диаметром 3 мм и толщиной L = 0,96 мм.
We present a new fast vertexing software for determination of the
primary vertex. The software is relying on the linear extrapolation
of tracks near the beamline, as the curvature of the track is negligible
for short distances. The method treats tracks as infinitely extended
ellipsoids, thereby transforming the vertex-finding problem into a
proximity one - between points with ellipsoidal error matrices. We have
implemented this approach in C++ using the NXV4 package for vector and matrix
operations. We have tested the resolution and speed performance on
SpdRoot simulated data, for the SPD experiment at JINR.
The unfolding of neutron spectra from Bonner multi-sphere spectrometer (BSS) measurements is an important task in radiation dosimetry. This study investigates the application of an Automated Machine Learning (AutoML) framework for neutron spectrum unfolding. To train and validate the model, a dataset of 5×10⁵ synthetic spectra was generated as weighted combinations of four spectral components: thermal, epithermal, fast and high energy. The performance of the developed algorithm was evaluated using a database of 340 experimentally measured spectra. The model was trained and tested on the JINR Multifunctional Information and Computing Complex. The LightAutoML and FEDOT frameworks were used to optimize the model through hyperparameter tuning and ensemble blending of multiple machine learning algorithms, including: L2-regularized linear regression, LightGBM, CatBoost and Random Forest. AutoML results were compared with the developed neural network model. Two spectra representation methods were evaluated: spectra discretization over the energy grid and Legendre polynomial expansion. The uncertainty in spectrum unfolding was estimated using a Monte Carlo approach, where random perturbations were introduced into the input data. To assess the unfolding quality, the following metrics were analyzed: Spearman and Pearson correlation coefficients, cosine similarity, cross-entropy, Wasserstein distance, Kullback–Leibler divergence, maximum mean discrepancy and coefficient of determination (R²). Based on the developed algorithm, a prototype web application was designed to facilitate spectrum unfolding in practical applications. The research was carried out within the state assignment of Ministry of Science and Higher Education of the Russian Federation (theme No. 124112200072-2).
Keywords: cloud technologies, knowledge-intensive applications, workflow management system, workflow as a service
1.Introduction
In this work, we propose a comprehensive solution to the problem of scheduling the execution of complex applications on cloud-based WaaS (Workflow as a Service) platforms. Multitenant WaaS environments allow to implement efficient mechanisms for managing continuous flows of diverse types of jobs in various fields of knowledge [1]. Workflow is a widely used model that can be represented in the form of a directed acyclic graph (DAG), where vertices correspond to single tasks and arcs to information links. Cloud technologies are actively used to perform scientific workflows, including: CyberShake (seismology), Epigenomics, SIPHT (bioinformatics), Montage (astrophysics), LIGO (physics of gravitational waves). The execution of such applications is automated by workflow management systems (WMS). They provide functionality for resource management, scheduling task execution and data transfers. To date, there are a huge number of WMSs: ASKALON, Galaxy, HyperFlow, Kepler, Pegasus, Taverna, CloudBus and a number of others [2].
2.Integrated Approach for Workflow Scheduling and Resource Management
The main strength of cloud computing is its scalability: Infrastructure as a Service (IaaS) allows WMS to access a virtually unlimited pool of resources. At the same time, a number of serious problems arise related to the algorithms and features of job-flow scheduling, the solution which critically affects the efficiency of resource utilization in cloud environment.
First of all, this is the problem of selecting appropriate IaaS providers, forming a pool of virtual machines (VMs), and allocating them on physical servers. As a rule, known solutions do not consider the issues related to simultaneous execution of tasks belonging to different workflows on one VM. Therefore, this leads to reduced utilization of active VMs, the need to deploy additional VMs and containers in them, which, in turn, causes the corresponding time costs and performance degradation.
Despite the fact that diverse types of workflows can be represented in the form of DAGs, the graph structures for different applications, for example, Montage, CyberShake and SIPHT, differ significantly by the computational complexity of their constituent tasks and types of information links. This creates additional challenges when executing heterogeneous workflows on a single WaaS platform. Another challenge is the natural presence of loops in a number of applications. For example, WMSs Pegasus, Apache Airflow, Taverna, Kepler resort to palliative methods to eliminate such loops, which leads to increased workflow scheduling time [2].
Considering the mentioned aspects, the need for an integrated approach for workflow scheduling and resource management in WaaS platforms determines the importance of the proposed solution. The scientific novelty of the approach consists in the development of multifactor strategies for workflow and resource management. The problems of efficient workflow execution should take into account the heterogeneity of resources of different IaaS providers and time costs for accessing global data storage, such as Amazon S3. Additionally, the specifics of each individual job must be taken into account. The scheduling must consider multiple user preferences and constraints, which include VM performance requirements, monetary cost of use and pay-per-use implementation, deadline constraints, power consumption, reliability, and several other aspects [3]. Thus, there is a need to develop multi-factor strategies for workflow and resource management.
3.Main Results
3.1. Methods and tools for scheduling independent and heterogeneous job-flows on WaaS platform.
Proposed scheduling methods and tools meet the following requirements.
Dynamically create a pool of VMs from different IaaS providers and containers, taking into account multiple factors: cloud platform utilization level, data storage and transfer policies, workflow structure and user estimates on the execution time.
The execution time is comprised of the following components: time of actual processing as the ratio of the computation volume to the CPU performance on the VM of the corresponding type; time for data transfer between subtasks of the job (including reading and writing to global storage); time to deploy VMs and containers in VMs of the corresponding type.
The WaaS platform is supposed to receive many workflows at any given time. Each workflow subtask can be executed on some particular subset of VM types available from the IaaS provider. Specialized mechanisms were implemented to resolve conflicts between tasks competing for the use of the same VMs.
3.2. Selecting a WMS and extending its functionality to implement the core components of the WaaS platform: workflow scheduler; resource provisioning manager; system for monitoring the state of resources and services of the platform; a system for storing workflow execution histories on the WaaS platform.
3.3. Experimental studies of multifactor workflow and resource management strategies on synthetic datasets and real applications available in open-source repositories [2].
Practical use of the received results is possible for various knowledge-intensive applications with high demands on computing resources of such distributed environments as cloud platforms. The project's code is hosted in the GitHub repository (https://github.com/Sorran973/Scheduling-in-Workflow-as-a-Service).
References
1. Toporkov, V. Job Batch Scheduling in Workflow-as-a-Service Platforms / V. Toporkov, D. Yemelyanov, A. Bulkhak, M. Pirogova // Proc. PCT 2024. Communications in Computer and Information Science. - 2024. V. 2241, Springer, Cham. - P. 65–79.
2. Amstutz, P. Existing Workflow systems [Электронный ресурс] https://s.apache.org/existing-workflow-systems / P. Amstutz, M. Mikheev, M. R. Crusoe, et al. (дата обращения 18.08.2024).
3. Toporkov, V. Micro-scheduling for Dependable Resources Allocation / V. Toporkov, D. Yemelyanov // Performance Evaluation Models for Distributed Service Networks. Studies in Systems, Decision and Control. - 2021. V. 343. Editors: Bocewicz, Grzegorz, Pempera, Jarosław, Toporkov, Victor. Springer International Publishing. - P. 81-105.
Over the past two years, the primary focus of JINR and its Member States cloud infrastructures has been on upgrading operating systems and core software. Significant efforts have also been directed toward deploying new applications and services on the JINR and JINR Member States cloud resources. This report provides a detailed overview of the main technical achievements and outlines the operational challenges faced during this period.
Two methods of population annealing implemented in a hybrid MPI/CUDA architecture are discussed. Examples of applications for classical statistical physics systems are given. The first method is based on annealing with temperature reduction/increase. It can also be used to minimize the functional. The second method is based on lowering/raising the energy of the system and allows investigating the details of the phase coexistence in the vicinity of the phase transition. Examples include parallel and distributed simulations of several million copies of the system under study.
-
-
-
The rapid growth in data volume and complexity has exposed the limitations of traditional storage solutions. While data lakes offer scalable handling of large and unstructured datasets, they fall short in integrating data across distributed sites - a critical requirement for modern workflows such as machine learning that demand seamless, aggregated access to diverse data sources.
In this study, we show a way for efficient implementation of an architecture, called Data Mesh, designed to unify independent data sites into a cohesive storage ecosystem. Our approach combines hierarchical storage techniques with advanced virtualization technologies. By deploying virtual container clusters and dynamic migration services, Data Mesh achieves high agility and scalability, enabling efficient data placement and real-time access across dispersed repositories. Central to our design is a distributed metadata layer that maintains a virtual representation of all data assets. That integration service orchestrates metadata synchronization and governs the interaction between hierarchical storage tiers and migration mechanisms. This unified virtual data plane facilitates seamless data discovery, governance, and analysis without compromising individual site autonomy.
Data Mesh represents the next step in evolution of storage architectures, addressing the needs of large-scale, multi-site projects. It offers a dynamic, scalable, and integrated platform capable of supporting demanding machine learning and analytics applications in complex environments.
-
The presentation is dedicated to a promising new scientific research direction called hybrid artificial intelligence. Hybrid AI means developing methods to combine the advantages of machine learning, strong mathematical models, and high-performance computing. This issue is considered in the context of solving large linear programming problems in real time. The following subjects are discussed.
- The specifics of using different types of parallelism: coarse-grained, fine-grained and micro-grained.
- The structure of AI technology.
- Deep neural networks as an universal tool for approximating complex functions: advantages of inference and difficulties with training.
- Linear programming as the most popular mathematical optimization model.
- The splendor and poverty of simplex method.
- Is there an alternative to the simplex method?
- New projection methods in linear programming.
- The poverty and splendor of projection methods.
- Is the combinatorial explosion so terrible?
- How to create an image of an affine subspace and feed it to a neural network.
- Will the projection method armed with a neural network be able to outperform the simplex method on a supercomputer?
-
Key words: DNA, quantum cellular automata, charge transfer, biocomputer
The emergence, development and important role that informatics plays in modern science is due to the explosive development of computer technologies. A new and more general direction is to consider bioinformatics as informatics on the bases of nanobioelectronics and biocomputer technologies. DNA molecular is an important example of data storage and biocomputing. Performing millions of operations simultaneously DNA – biocomputer allows the performance rate to increase exponentially. The limitation problem is that each stage of paralleled operations takes a very long time. To overcome this problem can nanobioelectronics [1]-[5]. The new branch of nanobioelectronics based on quadruplex quantum calculations is discussed.
Such processes as DNA quantum cellular automata dynamics , DNA charge transport , Bloch oscillations, soliton evolution, polaron dynamics, breather creation and breather inspired charge transfer are discussed. The supercomputer simulation of charge dynamics at finite temperatures is presented. Different molecular devices based on DNA are considered. These make the solution of quantum bioinformatics problems based on DNA technologies.
AI development brings a revolutionary changes to our life and our society.
The practical use of AI approaches for scientific studies is slightly behind the general use.
This lag is driven by a specific requirements to the machinery imposed by scientific use.
Using AI based fast simulation surrogate models for particle physics experiments is a popular trend nowadays.
In this presentation we will discuss typical approaches to developing fast models for simulating responses of different detectors,
limitations of such AI based approaches, possible ways to overcome those limitations.
Specific issues for using AI based surrogate models in mass data production will also be addressed.
В рамках комплексной программы «Развитие техники, технологий и научных исследований в области использования атомной энергии в Российской Федерации» в период с 2022 по 2024 годы для проведения исследований в области физики плазмы и управляемого термоядерного синтеза (УТС) было создано единое информационное пространство - FusionSpace.ru. (или аппаратно-инфраструктурная платформа информационно-коммуникационного пространства – АИП ИКП).
Основной целью FusionSpace.ru является объединение территориально распределенного экспериментального и научного потенциала исследовательских центров и ВУЗов Российской Федерации.
Важной задачей FusionSpace.ru в перспективе является предоставление российским ученым инструментария для работы с данными экспериментального термоядерного реактора ИТЭР (Установка ежедневно будет выдавать порядка 2,2 ПБ экспериментальных данных), в рамках международной коллаборации.
В докладе представлены основные технические решения и результаты проведения нагрузочных и комплексных испытаний АИП ИКП, а также результаты тестирования макета Российского Центра удаленного участия в экспериментах на установке ИТЭР (Remote Participation Center – RPC), расположенного на площадке «Проектного центра ИТЭР» в г. Троицк.
Работа выполнена в соответствии с государственным контрактом с Госкорпорацией «Росатом» № Н.4к.241.09.25.1054 от 07.05.2025 г. и рабочему соглашению IO/21/TA/4500000169 с Международной Организацией ИТЭР.
Integrating Large Language Models (LLMs) into high-energy physics (HEP) drives a paradigm shift in how researchers design experiments, analyze data, and automate complex workflows. There are examples in theoretical physics, e.g., L-GATr [1], as well as large physics models [2], which are large-scale artificial intelligence systems for physics research and applications. The development of Xiwu [3] and [4] underscores the potential of LLMs in formal theorem proving. Although LLMs are trained on systems with substantial computing power, potential users can leverage pre-trained LLMs to meet their requirements through the Retrieval-Augmented Generation (RAG) architecture, which assists researchers in finding answers within a domain-specific information.
Domain-specific information is often viewed as data from the Internet. However, specific cases make it more interesting to consider data within a narrow field of knowledge, as found in databases and/or a particular set of curated data, documents, or books that are accessible within the local network. Even in such circumstances, many details remain, such as the retrieval process, the choice of LLM, and the style of prompts, among others. Experimental physics encompasses many complex components, each of which is challenging to maintain in proper functioning. This leads to the assumption that future LLMs in RAG architecture will be addressed to specific topics, including the physics domain, complicated detectors, computing infrastructure, and other technical components. Here is an example of RAG for computing developers and administrators [5]. The RAG architectures and computing facilities for them are expected to be the main direction for future developments.
1. Jonas Spinner et al // Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics // https://arxiv.org/html/2405.14806v1
2. Kristian G. Barman et al // Large Physics Models: Towards a collaborative approach with Large Language Models and Foundation Models // https://doi.org/10.48550/arXiv.2501.05382
3. Zhengde Zhang et al // Xiwu: A basis flexible and learnable LLM for High Energy Physics // https://doi.org/10.48550/arXiv.2404.08001
4. Kefan Dong, Tengyu Ma // Beyond Limited Data: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving // https://doi.org/10.48550/arXiv.2502.00212
5. Alexey Naikov, Anatoly Oreshkin, Alexey Shvetsov, Andrey Shevel // The machine learning platform for developers of large systems // https://doi.org/10.48550/arXiv.2501.13881
-
The SPD Online Filter is a specialized data computing facility designed for the high-throughput, multi-step processing of data from the SPD detector. Its primary objective is real-time data reduction to minimize storage requirements and enable downstream analysis. The system combines a compute cluster with middleware that abstracts hardware complexity from the applied software.
This report details the system's architecture and illustrates how the platform is designed to meet the SPD experiment's demands for scalability, throughput, and operational resilience during real-time data processing. The system accomplishes this by coordinating data management, workflow orchestration, and workload management.
The article demonstrates the implementation of the Workflow Management System (WfMS) for the high-performance computing system for preliminary processing of SPD physical experiment data - SPD Online Filter. The capabilities of each WfMS microservice are shown and the key points of the system creation are identified. The talk also defines further plans for upgrading the system.
Pilot applications have become essential tools in distributed computing, offering mechanisms for dynamic workload execution and efficient resource management. They are commonly employed in high-performance computing and large-scale scientific experiments due to their flexibility and scalability. Despite their broad adoption, the field still lacks a standardized abstraction and consistent best practices, resulting in a diverse range of implementations with varying degrees of compatibility and effectiveness.
In this talk, we will examine the design and architecture of pilot applications, focusing on their core components and operational models. A particular emphasis will be placed on the concept of late binding, which enables adaptive task assignment and enhanced resource usage. We will present our approach — a two-part system comprising a pilot and a daemon — designed to meet the specific requirements of the SPD experiment. This system leverages multithreading to handle task scheduling, monitoring, and reporting efficiently. The presentation will highlight practical insights from applying pilot applications in distributed environments, with an in-depth look at their role in the SPD experiment.
The Baikal-GVD Deep-Underwater Neutrino Telescope is a cubic-kilometre detector currently being constructed in Lake Baikal. It generates about 100 GB of data daily. To obtain reliable high-quality data and to ensure stable operation of the detector, the online software has been developed. In the talk, we review the main components, architecture, principles of the software for data acquisition, as well as the logic of the trigger system, real-time monitoring of the detector and its control systems, data storage and transmission. The results of detector operation are presented as a data bank.
The Spin Physics Detector (SPD) is being built as a part of NICA mega-science facility in the Joint Institute for Nuclear Research. A design feature of the detector is the absence of a classical trigger system that allows event selection. This leads to the need to collect the entire set of generated signals from the subsystems. In this regard, the data flow from the detector can reach 200 PB/year. In order to reduce the amount of data for long term storage and subsequent analysis, it is planned to carry out their primary processing using a specialized computing system - SPD Online Filter. In this report, we present one of its components - a data management system that provides control over the data lifecycle.
Baikal-GVD is a gigaton-volume neutrino observatory under construction in Lake
Baikal. Its data processing software consists of a core part and a managing
part. The former is a set of C++ programs built upon the BARS (Baikal Analysis
and Reconstruction Software) framework, which provides a basis for
implementing all data processing stages. The Python-based management layer
organizes these programs into an executable processing graph, resolving
dependencies between them.
The system is designed with three levels of parallelism. First, different
detector clusters are processed independently on separate virtual machines
(VMs), with a dedicated VM merging their results. Second, each cluster data
processing is performed in two sequential workflows: Fast Processing (per-file
analysis within 2–13 minutes) and Offline Processing (full-run reprocessing
with higher precision, completed within 1–5 hours after a run). Each workflow
contains parallel processing sections.
This work focuses on the third level of parallelism: multi-threading within
the core BARS framework. The use of multi-threading allows for a sizeable
reduction of the algorithms' execution time, which can be particularly
beneficial for online data analysis tasks in the context of multi-messenger
astronomy.
Event Metadata System (EMS) of the BM@N experiment, the first experiment of the NICA project is an important part of the BM@N software ecosystem. Its latest version containing core necessary functions has been recently deployed in the JINR infrastructure. The Event Catalogue of the EMS has been filled with nearly 700M events collected by BM@N during its first physics run completed in February 2023, making it possible for collaboration members to search for required experimental events based on provided criteria, using both Web user interface and Application programming interface. The focus of the report is on recent improvements of the EMS, its usefulness for experiment data processing, and its integration with other software, including the BmnRoot software package, event visualization tool, and automatic deployment system.
Digital twins (DT) of distributed data acquisition, storage and processing centers (DDC) can be used to improve the technical characteristics of computing systems, make decisions on the choice of equipment configurations as part of the task of scaling and resource management. The report discusses a method for creating and using DDC digital twins. A distinctive feature of the method is the ability to model data processing and storage, taking into account the characteristics of data flows and job flows, the probabilities of failures and changes in the equipment performance. A software package has been developed based on the method. Verification and experimental operation of the software package was carried out during the creating DT for computing infrastructures for acquisition, storing and processing experimental data in the field of high-energy physics. In the future, it is planned to improve the developed method and add a multi-criteria optimization function when choosing an equipment configuration. As criteria, both more detailed technical parameters and cost parameters of the equipment included in the DDC will have to be taken into account. The web service for user interaction with the DT will be upgraded to improve the user-friendliness of the software package. The results of the work will make it possible to expand the functionality of using the software package in the tasks of designing, creating, supporting and developing DDCs for large scientific projects.
Доклад посвящен решению задачи производственного планирования при помощи квантового подхода. Основной идеей является постановка задачи в виде задачи линейного программирования, которая преобразуется в QUBO вид (Quadratic Uncnstrained Binary Optimization). Поставленную задачу можно решить как при помощи эмулятора квантового компьютера, так м при помощи классических солверов (например, Highs или Gurobi).
В [1] рассмотрено применение квантового отжига для задачи распределенного гибкого календарного планирования производств (DFJSP) на примере текстильной промышленности. А в [2] предложен подход решения задачи планирования проекта с ограничением на ресурсы (RCPSP), основанный на формулировке задачи в виде квадратичной бинарной оптимизации (QUBO).
Данная работа посвящена решению задачи производственного планирования. Заданы заводы и потребители. Для каждого завода заданы его максимальная производительность (по годам), максимальный срок хранения продукции, стоимость производства и др. Необходимо удовлетворить годовой спрос каждого потребителя с учетом дополнительных ограничений. Задача сформулирована в виде задачи линейного программирования, преобразована в QUBO вид и решена при помощи алгоритма квантового отжига.
[1] Toma, L., Zajac, M., Störl, U. (2024). Solving Distributed Flexible Job Shop Scheduling Problems in the Wool Textile Industry with Quantum Annealing. arXiv preprint arXiv:2403.06699. https://doi.org/10.48550/arXiv.2403.06699
[2] Papadimitriou, C., Hauke, P., Zoller, P., Leib, M. (2022). A QUBO formulation for the Resource-Constrained Project Scheduling Problem. Quantum Machine Intelligence, 4(1), 13. https://doi.org/10.1007/s42484-021-00066-8
Современное состояние квантовых вычислений характеризуется стремительным переходом от теоретических исследований к развитию технологии с высоким прикладным потенциалом. Данное исследование направлено на развитие методов анализа данных с использованием парадигмы квантовых вычислений. Высокоуровневые абстракции при проектировании квантовых схем помогают снизить когнитивный барьер для специалистов с опытом работы на классических компьютерах, способствуя внедрению квантовых алгоритмов в различные предметные области. Это позволяет сфокусировать внимание на решении предметных задач, а не на технических деталях их реализации. Предлагаемый подход поэтапного проектирования квантовых схем заключается в последовательном переходе от высокоуровневых шаблонов к практической реализации на квантовых программных симуляторах или квантовых компьютерах. Модульный подход позволяет использовать готовые библиотечные функции, содержащие оптимизированные реализации квантовых схем, что упрощает и сокращает время разработки, предоставляя возможность интеграции проверенных решений при моделировании квантовых алгоритмов. Современные языки и платформы для квантовых вычислений поддерживают модульность через библиотеки квантовых операций и подпрограмм, обеспечивают интеграцию с классическими вычислениями при моделировании гибридных квантово-классических алгоритмов. Основные результаты исследования включают формализацию композиционных правил при построении квантовых схем для встроенных шаблонов фреймворка PennyLane и гибридную интеграцию квантовых модулей для конвейера анализа данных.
This work introduces a novel architecture for progressive growing of quantum generative adversarial networks (PQGAN), designed to enhance image synthesis at high resolutions. Our implementation integrates a quantum-enhanced generator implemented as parameterized quantum circuits (PQC) utilizing data re-uploading strategies alongside strongly entangling layers for efficient representation learning. Building on the state-of-the-art QINR-QGAN generator, we grow the model progressively, inserting new data-re-uploading + entanglement blocks whenever the resolution doubles (4→8→14→28), and we smooth each hand‑over with standard α‑blending.
Experimental results on the MNIST dataset reveal that partial propagation of learned features from lower to higher resolutions significantly accelerates model convergence. Performance metrics—including Wasserstein Distance, FID, SSIM, and PSNR—demonstrate results comparable to QINR-QGAN, while requiring fewer training iterations for the final resolution.
These findings indicate the potential of the proposed PQGAN architecture to advance the efficiency and scalability of quantum-enhanced image generation.
Гибридная квантово-классическая генеративно-состязательная сеть с прогрессивным обучением для генерации изображений
В данной работе представлена новая архитектура прогрессивного обучения квантовых генеративно-состязательных сетей (PQGAN), ориентированная на улучшение генерации изображений высокого разрешения. Реализация включает квантово-усиленный генератор, построенный на параметризованных квантовых схемах с использованием стратегий повторной загрузки данных (data re-uploading) и сильно запутанных слоёв (strongly entangling layers) для эффективного обучения представлений. Основываясь на передовом подходе генератора QINR-QGAN, мы постепенно расширяем модель, добавляя новые блоки повторной загрузки данных и запутывания каждый раз при удвоении разрешения (4→8→14→28), при этом переходы между разрешениями сглаживаются с помощью стандартного α‑смешивания (alpha-blending).
Эксперименты на наборе данных MNIST показывают, что частичная передача извлечённых признаков с низких уровней разрешения на более высокие существенно ускоряет сходимость модели. Используемые метрики — Wasserstein Distance, FID, SSIM и PSNR — демонстрируют результаты, сопоставимые с QINR-QGAN, но при этом требуют меньше итераций обучения для финального разрешения.
Полученные результаты подтверждают потенциал предлагаемой архитектуры PQGAN для повышения эффективности и масштабируемости генерации изображений с применением квантовых вычислений.
При исследовании спин-обменного взаимодействия между атомами в газовой ячейке существует задача поиска условий, при которых данное взаимодействие происходит. Одним из таких условий является долгоживущая атомная пара в газовой ячейке, механизм формирования которой описывается ван-дер-Ваальсовым потенциалом. Примером реализации механизма является трехатомные столкновения, когда один атом может «забрать» излишек энергии оставив два других атома в потенциальной ловушке. Так при рассмотрении трехатомных столкновений, которые часто происходят в газовой смеси, только их малая доля приводит к образованию связанной атомной пары. Целью работы является демонстрация эффективности методов машинного обучения для распознавания формирования атомной пары по начальным условиям трехатомного столкновения. Были рассмотрены простые методы такие как «полиномиальная регрессия» в паре с «логистической регрессией», «градиентный бустинг», так и сложные: «многослойный перцептрон». В предоставленных данных частота формирования атомной пары была в соотношении 1 к 10000. В результате удалось в 2000 раз уменьшить количество рассматриваемых начальных условий, при этом не потеряв ни одного случая формирования атомной пары.
This paper is dedicated to the description of the application of a neural network approach to the numerical integration of single and double integrals and its implementation as a Python programming language library “Skuld”. The essence of the approach is to train a neural network model to approximate the integrand and then to use the parameters of the model to numerically calculate the value of the integral.
The usage of this approach can decrease time and computational complexity required to get a numerical integration result, especially when the number of integrand variables is large. Where the common numerical methods become too complex, this numerical approach allows calculations to be less demanding of the computational time and resources.
Single and double integrals are well integrated with common numerical methods, however, this work is a foundation for further development of the neural network integration library “Skuld” capable of numerical integration of multiple integrals, where the approach will unfold its advantages.
The paper describes the mathematical foundation of the approach and its software implementation: the “Skuld” library. The library was tested using Genz's test functions and was applied for calculations within the framework of a physics problem of modeling of meson properties in a QCD-motivated model with separable interaction kernel for the NICA experiment.
Modern distributed machine-learning pipelines must juggle three conflicting goals: compact storage, reliable data delivery, and strong security assurances across many independent sites. Traditional approaches achieve only two of the three, typically sacrificing either space efficiency (through triple replication) or verifiability (by trusting storage nodes). We introduce a lightweight overlay that combines high-rate erasure coding with leader-free Byzantine consensus and succinct zero-knowledge proofs. Training datasets are first split into coded fragments, stored as ordinary NeoFS objects, and then anchored by a minimal on-chain ledger that records fragment identifiers and cryptographic commitments. During training, each learner retrieves fragments in parallel, verifies constant-size proofs of authenticity on the fly, and reconstructs the original data even if several storage nodes fail or behave maliciously. The work outlines the core protocols, analyses trade-offs between redundancy, bandwidth, and verification latency. It provides design guidelines for integrating verifiable, space-efficient data pipelines into federated learning and other large-scale AI systems. The resulting architecture eliminates the replication tax while removing single points of trust, paving the way for secure, storage-aware machine learning at scale.
В работе представлен анализ современных подходов к обеспечению безопасности и интерпретируемости глубоких нейронных сетей через объяснительные визуализации в контексте противодействия состязательным атакам. Рассмотрены методы объяснимого ИИ, типы состязательных атак и современные стратегии защиты. Практически показано применение визуализаций Grad-CAM для выявления критических областей данных при атаках. В результате работы подтверждена эффективность интеграции объяснительных методов для создания более прозрачных, устойчивых и безопасных моделей искусственного интеллекта, пригодных к внедрению в ответственных сферах, в том числе для повышения надёжности и защищённости распределённых систем.
User authentication is one of the core components of any secure distributed computing system. Traditional methods typically rely on static, one-time verification steps (e.g., password entry at login), which leaves active sessions vulnerable to takeovers. In response to this challenge, the concept of continuous authentication (CA) has gained traction – an approach where user identity is verified repeatedly throughout the session using behavioural or contextual signals. This paradigm aligns closely with the zero-trust security model, which operates on the principle of “never trust, always verify.”
This work presents the architectural design of a hybrid continuous authentication system suitable for deployment in distributed computing platforms. It integrates machine learning-enhanced risk-based authentication (MLE-RBA) with keystroke dynamics analysis. MLE-RBA evaluates contextual factors such as device type, IP address, and access time to estimate the likelihood that a session is legitimate. Keystroke dynamics, in turn, provide a behavioural biometric based on how the user types, allowing the system to monitor for deviations from the legitimate user’s typing profile during the session.
The proposed system architecture combines these two methods in a risk fusion engine that periodically assesses both contextual and behavioural data to determine whether further authentication is required. This design is well-suited for distributed environments, where contextual signals may vary widely across nodes, and where keystroke-based biometrics can provide a consistent, user-centered verification layer. The approach improves resilience against credential theft and mid-session hijacking while minimizing user disruption.
While this paper focuses on architectural design, earlier experiments with MLE-RBA indicate that machine learning methods significantly improve anomaly detection over classical RBA approaches. The combination with keystroke biometrics is expected to further strengthen real-time detection of intrusions without imposing constant friction on the user.
This hybrid model lays the groundwork for secure, user-friendly authentication in distributed environments, and constitutes a promising direction for practical zero-trust authentication.
Keywords: continuous authentication, risk-based access, keystroke biometrics, anomaly detection, zero trust
Recent advancements in deep learning have significantly improved electrocardiogram analysis for early and accurate detection of cardiovascular diseases. Unlike traditional ECG interpretation methods, which depend heavily on expert judgment and are prone to variability, machine learning models automatically identify complex patterns within large ECG datasets, offering enhanced diagnostic accuracy. Convolutional neural networks and transformer-based architectures demonstrate superior sensitivity and specificity, facilitating real-time monitoring and continuous risk assessment through wearable technology.
Machine learning effectively addresses ECG signal challenges, including noise reduction and variability management, by automatically extracting relevant clinical features. Explainability techniques further enhance clinical interpretability and trust among healthcare providers. Additionally, the adoption of federated learning in ECG analysis allows collaborative model training across distributed data sources, ensuring patient privacy and improved model generalization across different clinics and devices.
We propose an end-to-end deep neural network-based tool specifically designed for cardiovascular disease detection, integrating advanced preprocessing techniques, deep feature extraction, and robust classification algorithms. The proposed solution demonstrates high diagnostic accuracy validated across diverse patient cohorts and varied clinical settings. Furthermore, it includes intuitive visualization and interpretability modules, enabling clinicians to clearly understand model predictions. This comprehensive tool is designed for seamless integration into clinical workflows, enhancing efficiency, enabling timely clinical decisions, and contributing to improved patient outcomes.
This work was carried out within the framework of a joint project between MLIT and LRB JINR to create an information system for automating the analysis of radiobiological experiments.
Among the various types of radiation-induced DNA damage, the most crucial and dangerous types are DNA double-strand breaks (DSBs). To visualize DNA DSBs, the immunofluorescence staining method is used, which is based on the detection of specific protein markers involved in the process of DNA DSB repair where proteins accumulate at the sites of DNA DSB occurrence, forming radiation-induced foci (RIF). The number of RIF is typically assessed by visual inspection. However, manual scoring is a time-consuming work and prone to human error.
To automate the RIF analysis, we have followed a deep learning approach which consists of two stages; first a pretarained neural network called SAM2 is used to detect the cells in each image, then the trained neural network YOLO (You-Only-Look-Once) on our foci-annotated data is used to detect foci in each cell. Based on this model, we have developed a web service on the Writer Framework. The web service allows the user to observe the identified cells in the uploaded fluorescent image, choose the desired cells, automatically get the marked foci in each cell image and receive the numerical tables which include an assessment of the cell area, the number of RIF per cell and the average number of RIF in the image. The web service was developed and deployed on the basis of the ML/DL/HPC ecosystem of the heterogeneous HybriLIT platform and is available on the website https://mostlit.jinr.ru .
Keywords: Web service, deep learning, data analysis, DNA double-strand breaks, radiation-induced foci, radiobiology.
Acknowledgments: The study was carried out within the framework of the state assignment of Ministry of Science and Higher Education of the Russian Federation (theme No. 124112200072-2).
В докладе представлены результаты исследования возможности применения различных нейросетвых архитектур в задаче распознавания вертикальной и горизонтальной двигательной активности мелких лабораторных животных в тест-системе «Открытое поле» с получением дополнительной информации о временных интервалах действий. Работа выполняется в Лаборатории информационных технологий ОИЯИ в рамках совместного проекта ЛИТ и ЛРБ по созданию информационной системы для автоматизированного анализа данных радиобиологических экспериментах.
Был создан аннотированный набор видеоданных, с поведением грызунов (горизонтальное и вертикальное положение), размеченный покадрово, для решения задачи бинарной классификации действий животных с иллюстрацией примеров разметки, на основе которого обучались и тестировались модели.
Было проведено исследование эффективности обучения нейросетевых моделей при использовании различных стратегий обучения, а также различных значений гиперпараметров. Приведён сравнительный анализ эффективности моделей Swin Transformer Tiny, ResNet-18, MobileNetV2, EfficientNetB0 и ConvNeXt-Tiny с использованием основных метрик качества и матриц ошибок.
Работа выполнена в рамках государственного задания Министерства науки и высшего образования Российской Федерации (тема № 124112200072-2).
В работе представлена разработка веб-сервиса для анализа траектории мелких лабораторных животных, полученных в поведенческих экспериментах на тест установке «Водный лабиринт Морриса» на основе разработанных алгоритмов с применением методов компьютерного зрения и глубокого обучения. «Водный лабиринт Морриса» — это поведенческий тест для изучения когнитивных функции и пространственной памяти у грызунов. Однако для анализа огромного количества экспериментальных данных возникла необходимость разработки удобного инструментария, которая может предоставить возможность получения не только траектории движения животного, но и классифицировать их и получать необходимые проанализированные количественные данные поведенческой реакции мелкого лабораторного животного при прохождении теста. Данная работа ведется в рамках совместного проекта ЛИТ и ЛРБ ОИЯИ, которая направлена для создания информационной инфраструктуры для анализа данных радиобиологических исследований.
Веб-сервис разрабатывается и развернут на базе экосистемы ML/DL/HPC Гетерогенной вычислительной платформы HybriLIT.
Работа выполнена в рамках государственного задания Министерства науки и высшего образования Российской Федерации (тема № 124112200072-2).
Ключевые слова: компьютерное зрение, алгоритмы глубокого обучения, Веб-сервис, автоматизация анализа данных, радиобиология, поведенческий тест «Водный лабиринт Морисса».
In this work, we present a fully automated method for delineating the “Open Field” experimental arena to support subsequent tracking of laboratory animal behavior. The core of our approach is the SOLD2 neural network model from the Kornia library, which provides high-quality detection of the arena’s linear boundaries and interior sectors without any manual intervention.
The processing pipeline consists of four main stages:
1. Line Detection with SOLD2
The model extracts all prominent linear features in each video frame, capturing both the outer contour of the arena and its internal divider lines.
2. Geometric Reconstruction
By computing intersections and extensions of the detected line segments, we reconstruct the arena’s layout and generate a sector map aligned to a common real-world coordinate system.
3. Segmentation-Based Tracking with YOLO11
A YOLO11 segmentation model, fine-tuned on a small manually annotated dataset, locates the animal within the perspective-corrected frame and outputs its trajectory as a time-series of coordinates mapped to the delineated sectors.
4. End-to-End Automation
All stages are integrated into a single, automated pipeline—from initial video ingestion and homography calibration to the production of final movement trajectories, each tagged with its respective arena zone.
This neural-network-driven framework eliminates the need for hand-drawn annotations and guarantees robust, reproducible performance across variable lighting conditions, camera angles, and apparatus modifications. By dramatically reducing data preparation time, it enhances the throughput and reliability of quantitative behavioral analyses in neuroscience and pharmacology.
Доклад посвящен разработке инструментария для автоматизации процесса морфологического анализа клеток сенсомоторной коры головного мозга с использованием моделей машинного обучения. Создаваемый инструментарий включает обученные модели для обнаружения, сегментации и классификации клеток нервной ткани на изображениях; веб-приложение, предназначенное для использования конечными пользователями, и набор вспомогательных утилит. Проведено исследование использования открытых и проприетарных наборов данных при обучении нейросетевых моделей. Представлен алгоритм полуавтоматизированного аннотирования изображений микропрепаратов, предназначенный подготовки собственного набора данных. Проведен сравнительный анализ эффективности использования моделей на основе архитектур U-Net, Mask R-CNN для сегментации клеток и архитектуры YOLO для обнаружения и классификации клеток. Разработан прототип системы в виде веб-приложения для автоматической разметки изображений, в которую интегрированы рассматриваемые нейросетевые модели. Она предназначена для использования конечными пользователями.
Работа выполнена в рамках государственного задания Министерства науки и высшего образования Российской Федерации (тема № 124112200072-2).
Monitoring agricultural land and the crops grown on it can significantly improve the accuracy and objectivity of information on the use of agricultural land. The paper proposes an approach that can be used to build a system for such monitoring of the state of a certain territory. Within the framework of this approach, satellite images of a given territory are processed. First, medium-resolution multispectral satellite images are requested for the spring and summer periods. The obtained images are processed and maps of the distribution of vegetation indices NDVI, SAVI, EVI and MSAVI are formed. These maps are then clustered to detect areas of vegetation. For the identified areas, higher resolution satellite images are additionally obtained, which serve as input for the deep neural network. This neural network is pre-trained to identify crops from known satellite datasets. The results of the neural network are maps of the distribution of crops grown on the territory, which are stored in a database for further analysis. During the monitoring process, satellite images are requested at regular intervals, which allows tracking the dynamics of the development of these crops from sowing to harvesting. The proposed approach allows for fairly accurate segmentation of agricultural lands and types of crops grown on them and monitoring of their changes in the monitored area.
The article presents the results of an attempt to solve the problem of finding the optimal route for a vessel. The vessel moves under the risk of collision with moving objects. Optimality is determined by the vessel's fuel consumption and arrival at the destination on time. To numerically determine the optimality of the path, a functional depending on the route is used. The solution to the route construction problem is to find the minimum of the functional. The article presents the results of solving this problem using various methods for finding the minimum. To determine the value of the functional, a program is used that allows the user to uniquely build a route and determine its optimality based on the values of a number of parameters. The algorithm for solving the problem is implemented in the Python programming language. To determine the value of the functional in the solution search program, a request is sent to the route construction program via sockets. The article compares the results of various minimum search methods applied to this problem.
В данной работе представлена гибридная методология численного моделирования турбулентных течений, основанная на сочетании волновой модели несжимаемого потока Шредингера (Incompressible Schrödinger Flow, ISF) и субсеточной фильтрации больших вихрей (Large Eddy Simulation, LES). Волновой подход ISF обеспечивает альтернативное описание динамики потока через эволюцию комплексной амплитуды, что позволяет естественным образом учитывать крупномасштабные вихревые структуры и особенности когерентной турбулентности. В то же время, методы LES обеспечивают эффективное подавление нерешаемых мелкомасштабных колебаний, сохраняя физически обоснованную модельную диссипацию. Предлагаемый гибридный подход направлен на объединение этих двух перспективных направлений, обеспечивая баланс между численной устойчивостью, физической достоверностью и вычислительной эффективностью. Особое внимание в работе уделяется реализации данного подхода в высокопроизводительной вычислительной среде (HPC), что позволяет использовать возможности параллельных архитектур и масштабируемых алгоритмов. Реализация построена с учетом требований к энергоэффективным вычислениям и использует механизмы гибридного параллелизма, что позволяет адаптировать модель к широкому спектру задач — от фундаментальных исследований до прикладных инженерных расчётов. Рассматриваются теоретические основания гибридизации, алгоритмические аспекты взаимодействия ISF и LES компонент, а также постановка численных экспериментов. Представленные результаты подчеркивают научную и прикладную значимость волновых методов в современной турбулентной гидродинамике и обосновывают потенциал их интеграции в HPC-платформы.
In federated synthetic data generation, model queries can expose statistical patterns, labeling behavior, and membership information—creating complex, layered privacy vulnerabilities. To this end, we propose PATE-FL: a federated learning framework that combines the PATE mechanism, Rényi Differential Privacy (RDP), and Paillier additive homomorphic encryption (HE), designed for the context of synthetic data generation under strict privacy requirements. In this study, we replace the gradient exchange in traditional federated learning with the voting result of the teacher model and implement secure aggregation through additive HE to effectively reduce the potential risk of information leakage during the query process. To support multi-node deployments, we introduce the Raft consensus mechanism to achieve state synchronization and fault tolerance. Considering the demand for query control and budget monitoring in practical scenarios, we design and implement a privacy management module to quantify the privacy cost of heterogeneous queries. To validate the effectiveness of these mechanisms under attack scenarios, we develop an internal testing pipeline to assess the system’s resistance to membership inference attacks (MIA) and attribute inference attacks (AIA). The proposed system integrates privacy safeguards and query monitoring mechanisms, demonstrating practical potential for cross-institutional deployment in privacy-regulated environments.
Moving to a new stage of implementation of storage systems, completely new technologies are required that can implement the proposed concepts on computing equipment. This study generalizes virtualization and hierarchical systems technologies and offers a practical implementation of the Data-mesh concept. This architecture is the most advanced solution in the field of storage systems and requires technologies of both cloud systems and grid approaches to computing. In the practical part of this work, a prototype of the system implemented using docker, kubernetes and python services is shown. All this is one node, which will subsequently be integrated into the global system by working with metadata at upper levels in a system known as Data-mesh.
The study touches upon the relevant topic of ensuring the security of the Internet of Things (IoT), in particular, to prevent distributed denial of service (DDoS) attacks. Currently, especially in the context of active use of IoT on the African continent, it is necessary to constantly pay attention to a detailed study of DDoS attack vectors, detection of network traffic anomalies, as well as the issue of timely counteraction to the large-scale use of botnet orchestrations based on artificial intelligence (AI). In order to form an adaptive tool for detecting DDoS attacks, it is proposed to use a set of software libraries (intelligent framework) based on long-term short-term memory (LSTM) algorithms, self-organizing map (SOM), and models based on adaptive resonance theory (ART). To evaluate the effectiveness of recognition, such indicators as F1 score, recall, and accuracy are used. The proposed methodology will allow creating a model of an intelligent IoT security system using advanced protection strategies.
The article uses the example of the automatic measurement monitoring subsystem (AMMS) to consider the organization of proactive maintenance for monitoring measurement channels for reading information from sensors of the Industrial Internet of Things (IIoT). In order to improve the quality of proactive monitoring, it is proposed to use the tools underlying the software package of invisible industrial intelligence of the environment (IPIIE). In addition, the study shows that the concept of proactive monitoring must be functionally supplemented with a new Edge AI technology or artificial intelligence (AI) technology that operates on devices located near the signal source. Edge AI technology involves collecting data from sensors, locally processing this data using AI models, and using the obtained results to perform certain actions, such as sending notifications. Thus, the development and use of such AI-based innovations, especially with the use of machine learning (ML) algorithms and invisible intelligence of the environment, allows us to bring the capabilities of proactive monitoring to a new, more effective level.
The article proposes a concept for creating a distributed platform (DP) to improve the quality and accelerate development in the field of IT technologies. The role of database management systems (DBMS) for building a system for collecting, storing and processing data when building a DP, where a large amount of heterogeneous data is collected within a single platform, is considered.
By creating a local development environment within the platform and deploying the required software, developers will be able to fully work with data, for example, gain direct read access to data streams (Kafka, RabbitMQ, gRPS), connect to raw or processed data suitable for solving a given problem and stored in a data ecosystem (EDS), as well as find a ready-made solution and apply it to their own data. In addition, it is possible to create distributed data sets from the EDS, and then use data analysis systems integrated into the platform. This is especially important when using artificial intelligence tools, where large volumes of raw and prepared data are needed to train and test models based on neural networks. The platform can also be used to provide services in the formats of data as a service and function as a service.
Современные распределённые вычислительные системы, такие как инфраструктуры интернета вещей (IoT), характеризуются высокой динамичностью, децентрализацией и гетерогенностью устройств, что предъявляет особые требования к механизмам эффективного распределения вычислительных и энергетических ресурсов между множеством конкурирующих и динамически поступающих задач. В условиях ограниченной информации, изменяющейся среды и отсутствия единого центра управления традиционные централизованные алгоритмы планирования демонстрируют низкую адаптивность, ограниченную масштабируемость и уязвимость к сбоям отдельных компонентов.
В докладе рассматривается интеграция аукционных механизмов и мультиагентных технологий как перспективного подхода к организации оптимального распределения задач и ресурсов в распределённых вычислительных системах. Мультиагентные системы (MAS) позволяют моделировать вычислительную инфраструктуру как совокупность автономных программных агентов, каждый из которых представляет отдельное устройство, сервис или пользователя. Эти агенты способны самостоятельно принимать решения, конкурировать за ресурсы, координировать свои действия и адаптироваться к изменяющимся условиям среды, что обеспечивает масштабируемость, устойчивость и гибкость всей системы.
Механизмы аукционов, интегрированные в мультиагентные системы, позволяют формализовать процесс распределения ресурсов как протокол, в рамках которого агенты выражают свои предпочтения и ценность задач посредством ставок (bid), а итоговое распределение определяется на основе этих заявок и установленных правил аукциона. Использование различных типов аукционов позволяет учитывать специфику задач, ограниченность ресурсов и динамику поступления заявок.
Таким образом, комбинация аукционных протоколов и мультиагентных технологий способствует формированию самоорганизующихся систем, в которых распределение ресурсов становится не только справедливым и прозрачным, но и стимулирует честное поведение агентов, минимизируя манипуляции и способствуя достижению глобальной эффективности. В таких системах агенты способны обучаться на основе локальных наблюдений и взаимодействий, что позволяет реализовать адаптивные стратегии в условиях неполной информации и высокой изменчивости среды.
The Spin Physics Detector (SPD) experiment is being built at the LHEP site of the Joint Institute for Nuclear Research, including a full software suite for every stage of data processing. Based on the Technical Design Report, the collaboration anticipates high luminosity, which will generate large volumes of data. To handle this workload at scale, we must either launch hundreds of nearly identical processing tasks by hand, including manual parameter collection or develop a specialized system to streamline, automate routine steps and gather all actions needed to start task in one place. In this talk, we present the design and work done of such production control panel system.
The ATLAS EventIndex is the complete catalogue of all ATLAS real and simulated events, keeping the references to all permanent files that contain a given event in any processing stage. The Event Picking Service (EPS) is a part of the EventIndex project. It automates the procedure of finding the locations of large numbers of events, extracting and collecting them into separate files. It supports different formats of events and has an elastic workflow for different input data. From time to time some errors occur while performing different workflows and threads. Some of these errors are situational, such as losses of connections to external services, and do not require any action from the user to fix them. The service detects such errors and restarts the necessary job chains automatically. Fixing other type of errors requires specific actions from the administrators of the services. The EPS finds such type of errors and reports them. Finally, the third type of errors that can occur are those that require a lot of time and effort from the developers to correct, but as a result, adding new methods allow them to be avoided automatically in the future.
In modern scientific computing, optimizing software performance is critical, especially for resource-intensive processes such as event reconstruction in high-energy physics experiments. The SpdRoot package, based on FairRoot, faces challenges with slow event processing, increasing the needs in computing time and resources. This study is aimed to identify and eliminate bottlenecks in SpdRoot’s source code to improve event reconstruction speed and computational resource usage. The methodology includes static code analysis using PVS-Studio, and Python libraries (pandas, matplotlib) for data processing and visualization. Key issues identified in the code include: integer overflow risks, unsafe type casting, memory leaks, missing copy constructors, and logical errors in control structures. Proposed fixes, such as memory operation optimization and elimination of undefined behavior, slightly reduced average reconstruction time per event without compromising output integrity. These results highlight the potential for further code optimization based on the proposed methodology, particularly relevant for NICA experiments, where processing speed directly impacts research efficiency.
Метод Монте-Карло находит широкое применение в метрологии, особенно при решении задач трансформирования распределений для оценки неопределенности измерений. Согласно Приложению 1 к Руководству по выражению неопределенностей (GUM) [1], данный метод является рекомендуемым инструментом для анализа измерительных моделей, заданных математическими зависимостями.
Среди преимуществ метода Монте-Карло можно упомянуть: точное оценивание неопределенностей при косвенных измерениях, корректную работу с асимметричными распределениями входных величин и / или нелинейными моделями, не допускающими линеаризацию, возможность использования нестандартных моделей входных распределений. В отличие от классических подходов, метод не требует априорных предположений о виде распределения выходной величины (традиционно предполагаемого нормальным или t-распределением) и позволяет оценивать полный набор статистических характеристик, а не только параметры рассеяния.
Существует достаточно широкий спектр программ, реализующий данный подход.
В настоящей работе представлена программная реализация метода трансформирования неопределенностей, включающая: выбор из некоторых типовых семейств распределений для описания входных величин, алгоритмы подбора параметров распределений по экспериментальным данным, механизм задания закона трансформирования посредством аналитических выражений, комплексный расчет статистических показателей выходной величины.
Рассмотрен вопрос о параллелизации проводимых вычислений.
[1] Evaluation of measurement data - Supplement 1 to the “Guide to the expression of uncertainty in measurement” - Propagation of distributions using a Monte Carlo method Joint Committee for Guides in Metrology, JCGM 101:2008.
Развитие современных математических сопроцессоров таких, как видеокарты NVIDIA и AMD, привело к широкому внедрению нейронных сетей в научные вычисления. В частности, на основе машинно-обучаемых межатомных потенциалов предложены более эффективные методы молекулярно-динамического моделирования с использованием преимуществ гибридной архитектуры современных суперкомпьютеров.
Данный подход особенно актуален для моделирования и исследования свойств новых композитных материалов. Классические межатомные потенциалы испытывают трудности в решении подобных задач вследствие того, что они не учитывают специфику химических связей между составными частями композита. Для учета таких особенностей удобно использовать нейронную сеть Бехлера-Парринелло на основе одноименных симметричных функций, так как она обучается на данных квантово-химического моделирования.
В данной работе представлен программный пакет, в рамках которого предложен вариант реализации этой нейросети на основе языка программирования Python и фреймворка PyTorch. Все вычисления производятся через тензорные операции фреймворка, поскольку форма функций Бехлера-Парринелло позволяет осуществить векторизацию вычислений. Проект имеет интерфейс для пакета ASE, который делает доступным молекулярно-динамические эксперименты с использованием нейронной сети. Пакет протестирован на ряде классических и квантово-химических моделей таких, как потенциал Леннарда-Джонса и идеальные кристаллы IB металлов. Показано, что использование данного подхода дает релевантные результаты при минимуме затрат на написание и сопровождение программного кода.
At present, Bonner multi-sphere spectrometers are considered reliable devices for assessing radiation conditions at high-energy physics facilities. However, the unfolding of the neutron spectral density function from the results of such measurements, from a mathematical point of view, belongs to the class of ill-posed inverse problems requiring various regularization methods. As such a method, we propose to use truncated singular value decomposition (TSVD), which allows not only the regularization procedure to be carried out, but also makes it possible to determine the optimal set of spectrometer moderator spheres for performing correct measurements. To unfold the neutron spectrum, we use its representation as a superposition of shifted Legendre polynomials, the number of which is determined by the degree of accuracy of the unfolding. Moreover, in order to match the accuracy of the unfolded neutron spectrum with the required measurement errors, we also use an iteration procedure, which allows us to improve the accuracy of unfolding. To illustrate our approach to unfolding neutron spectra and selecting sets of spectrometer moderator spheres, we use experimental data obtained at the JINR facilities - Phasotron and IREN.
Modern distributed intelligent agent-based systems face the need to adapt to dynamic environmental conditions, which requires the development of flexible reconfigurable architectures, as well as methods for optimizing policy and agent interaction. The Adaptive Multi-Agent Intelligent System considered in this paper includes applied and system software agents that are capable of acting rationally and accumulating experience. The perception of the application software agents is realized using Multi-Agent Deep Reinforcement Learning techniques, and high-level reasoning using Cognitive Data Structures and logical inference. Applied software agents collaboratively solve complex users' tasks, system software agents manage distributed computing resources by interacting with the Operating System and microservices. The software modules associated with system software agents are part of the specialized library, which is less demanding on computing resources and provides better performance than universal system libraries. To improve performance and reliability, uses scaling, where agents and microservices are duplicated and run on different compute nodes, as well as load balancing and optimization of resource consumption during task execution, are used to improve performance and reliability.
В статье предлагается модель когнитивной архитектуры робототехнического агента на основе человеко-машинного интерфейса. Цель – повышение автономности медицинских робототехнических средств для пациентов с нарушениями двигательной и речевой активности. Рассматривается случай, когда пациент не может использовать стандартные интерфейсы управления инвалидной коляской. Эксперименты демонстрируют возможность бесконфликтного взаимодействия нескольких агентов-колясок на основе глобальной команды, синтезированной пользователем, без прямой межчеловеческой коммуникации.
Одним из важных видов экспериментальных данных является многоканальное изображение. В нем число каналов может быть больше трех и доходить до сотен. Подобные данные возникают, например, в областях дистанционного зондирования Земли, пространственно разрешающей масс-спектрометрии, онкодерматологии. Всякий раз, когда появляется необходимость экспертной оценки многоканального изображения, возникает задача визуализации. Задача визуализации многоканальных изображений (ВМИ), состоит в том, чтобы преобразовать многоканальное изображение в трехканальное с максимальным сохранением важной для человеческого восприятия информации.
В общем случае при решении задачи ВМИ невозможно одновременно гарантировать:
1. сохранение между соседними пикселями всех границ, присутствующих в каналах исходного изображения;
2. консистентность визуализации, которая состоит в том, что исходно спектрально близкие пиксели будут иметь близкие интенсивности в результате.
Однако существуют методы, гарантирующие сохранение отдельно консистентности (PCA, UMAP).
В данной работе исследуется метод Соколова, являющийся консистентным по цветности и сохраняющий границы за счет манипуляции яркостью результирующего изображения. Благодаря такому распределению два свойства ВМИ оказываются согласованы с функциями ахроматической и хроматической контрастной чувствительности глаза, что предполагает существенное преимущество метода Соколова. Для проверки этого предположения в работе представлен специальный набор синтетических данных, на котором проведено сравнение известных методов визуализации. Результаты анализа подтверждают преимущество метода Соколова.
Accurate classification of plant diseases is crucial in agriculture, yet the development of accurate deep learning models often requires large and diverse datasets. Generative Adversarial Networks (GANs), introduced in 2014 and popularized for image synthesis in subsequent years, offer a promising approach for generating synthetic training samples beyond traditional augmentation methods such as rotation, resizing, cropping, flipping, brightness and contrast adjustments. Unlike basic augmentations, GANs are capable of creating more complex and realistic images, potentially improving model performance in data-scarce scenarios.
This study reviews recent advancements and applications of GANs in the context of plant disease detection, with a focus on their effectiveness as data extension tools. Several research works are analyzed, and various GAN architectures are evaluated—including DCGAN, WGAN, StyleGAN, and feature-transfer models like CycleGAN—on a dataset of 68 plant disease classes with sample sizes ranging from 15 to 200 images per class. The evaluation considers both the visual quality of the generated images and their impact on classification accuracy.
The findings highlight the strengths and limitations of each approach, providing practical insights into the applicability of GAN-based data extension methods for enhancing plant disease classification models trained on limited datasets.
Численные эксперименты с моделью эпидемии Covid-19 в Москве показали, что при репродукционном числе R0 около 4 происходит качественное изменение поведения (бифуркация) системы “вирус-человек”. Ниже этой величины (что мы наблюдали до 2022 г.) длительный (многолетний) прогноз стремиться к незатухающим колебаниям, выше – описывается затухающими колебаниями: амплитуды волн эпидемии становятся все меньше и меньше, при постоянном, очень высоком фоновом уровне заболеваемости, поддерживающем состояние естественного иммунитета на уровне близком к 100% (для современного значения R0 около 16 получаем 93.7%). В пределе система стремится к устойчивой точке равновесия. Дальнейшее увеличение контагиозности вируса меняет картину несущественно – более заразных штаммов можно не опасаться. Основным предположением данного исследования является неизменность функции сохранения иммунитета (в том числе для различных штаммов).
Dementia, particularly Alzheimer's disease, is a growing global medical and economic problem, exacerbated by increasing life expectancy and an aging population. This requires effective methods for processing biomedical research data, in which the number of observations is less than the data dimension. This article describes a comprehensive data processing pipeline, including dimensionality reduction and clustering. The methodology is based on the combined use of principal component analysis (PCA) and uniform manifold approximation and projection (UMAP) to reduce dimensionality followed by clustering with optimized parameters. The study demonstrates how these methods can mitigate problems such as sparsity of data and the curse of dimensionality by providing information about potential biomarkers for early diagnosis of neurodegenerative diseases. This study provides a foundation for experts in the field to explore new hypotheses and improve examination tools.
Представлена разработка мультимодальной системы, объединяющей методы объяснимого искусственного интеллекта (XAI) и генеративные технологии для автоматизации анализа рентгеновских снимков грудной клетки. Основное внимание уделено интеграции сверточных нейронных сетей, адаптированных для диагностики хронической обструктивной болезни лёгких, с алгоритмами интерпретации прогнозов и генерации текстовых медицинских заключений.
Система использует сверточную нейронную сеть EfficientNetB0, дообученную на специализированном датасете рентгенограмм. Для повышения прозрачности модели реализованы ме-тоды Grad-CAM и LIME, визуализирующие области снимков, влияющие на принятие решений. Генеративная часть системы основана на большой языковой модели DeepSeek-R1-8B-Medical-GGUF, формирующей структурированные отчёты с учётом анатомических особенностей и клинической значимости выявленных признаков.
Описанная конвейерная архитектура объяснений универсальна: применима не только в рамках медицинских сценариев, но и в других прикладных сферах, таких как обработка экспериментальных данных; в сферах, где пользователю необходим инструмент для автоматизированной обработки изображений с генерацией текстовых заключений. Для специализирован-ных областей, требующих быструю обработку больших объемов данных, мультиуровневая конвейерная архитектура поддерживает интеграцию в системы распределенных вычислений.
Разработанное решение прошло валидацию на клинических данных, продемонстрировав соответствие требованиям практической радиологии. Система предназначена для использования в качестве вспомогательного средства диагностики, обеспечивая врачей объективной интерпретацией результатов и снижая нагрузку на специалистов-рентгенологов.
Clinical target volume (CTV) is a traditional target delineation method used in radiotherapy. The concept however has several limitations (such as binary conceptualisation, variability and uncertainty). More recently a continuous probabilistic concept - Clinical Target Distribution (CTD) has come into prominence, which addresses these limitations. We report here a neural-network implementation of CTD identification in the treatment planning system and compare it to simulated MRI "ground truth". The CTD method achieves superior normal tissue sparing (mean OAR dose reduction: 29.3%) while maintaining 98.2% target coverage.
Nowadays, Secure Data Transfer (SDT) is a crucial part of data exchange processes, especially in cross-organizational environments. Such data exchanges often rely on untrusted public networks, which are known to suffer from data loss, corruption, and even unauthorized data access.
To address these challenges, we propose the use of a blockchain-based system with a message broker-like architecture. This architecture offers a convenient message delivery interface while relaxing data size limitations through the use of off-chain storages.
In this article, we present a prototype of a system based on the architecture mentioned above, built on the Hyperledger Fabric platform. The prototype follows a two-layer model, implemented using the support for multi-channel networks provided natively by the underlying blockchain platform. The first layer consists of multiple small PBFT clusters (referred to as partitions), which are used directly for message delivery. The second layer organizes these partitions into larger RAFT-managed clusters (referred to as topics), which handle system management and asynchronous data replication.
In addition to the blockchain core, the prototype includes connector applications that allow counterparties to interact with the blockchain, and off-chain storage systems used to store the actual data being transferred. The connector applications are implemented as Java-based microservices. PostgreSQL databases and MinIO object storage are used as the off-chain storage components.
All data transfer logic is implemented via Java-based chaincodes, which are responsible for orchestrating the data transfer process and manipulating blockchain ledgers. These ledgers serve as immutable logs of all data transfer processes between counterparties and can be used for auditing purposes.
As a result, the presented prototype offers enhanced fault tolerance and scalability compared to existing blockchain approaches and traditional message brokers.
Personal data anonymization is an important step in dataset preprocessing, especially when dealing with sensitive information. However, the impact of this process on the quality of clustering remains poorly understood. The presented study analyzes the impact of different anonymization techniques affect the clustering results. The experimental part of the work is based on the application of ISODATA, maximin distance (Maximin) and hierarchical clustering algorithms to different datasets. The results obtained demonstrate that, for a limited number of features, depersonalization contributes to a clearer separation of the resulting clusters and while preserving the overall data structure and its trend. These findings indicate a future problem with the risks of personal data de-identification.
The paper proposes a method for hidden encryption of text information that combines the symmetric AES algorithm and elements of visual steganography. The text is encrypted using a 128-bit key presented in hexadecimal format, and the encryption result is also converted into hexadecimal blocks. A JPG image is used as a container, which is segmented into fragments. The coordinates for embedding encrypted data are determined based on paired key values. Each block of encrypted text is encoded as a color value and embedded in the corresponding image segment. The proposed approach provides an additional level of security by combining cryptographic and steganographic protection.
The computing cluster at the NRC «Kurchatov Institute»—IHEP is a complex system integrating multiple diverse components and technologies. These include distributed computing, high-performance computing , highly reliable uninterruptible power supply systems, precision cooling systems, and information and communication technologies. Monitoring the system's status, analyzing its behavior, and managing its operation present a highly challenging task that can be broken down into several subtasks. This paper describes the current state of the system for collecting and analyzing the computing cluster’s parameters and its management.
-
Современные подходы к подготовке специалистов в сфере информационных технологий предполагают тесную связь теоретического обучения с воспроизводимыми практиками, приближенными к промышленным условиям. Особенно актуальной становится задача организации таких учебных сред, которые позволяют моделировать полный жизненный цикл программного обеспечения от размещения исходного кода, до развёртывания собранного приложения в производственном или тестовом контуре. При этом всё большую значимость приобретают открытые и свободно распространяемые компоненты, позволяющие отказаться от использования внешне зависимых или коммерчески ограниченных программных продуктов.
В докладе описывается архитектура образовательной облачной среды, реализующей автоматическое развёртывание и взаимодействие компонентов, традиционно включаемых в DevOps-инфраструктуру. Среда построена по принципу полной автоматизации, начиная с установки всех необходимых сервисов — Git-сервера, хранилища артефактов, управляющей системы для конвейеров сборки, контейнерного оркестратора — и заканчивая конфигурацией и запуском пайплайнов для доставки программных решений в различные вычислительные среды.
Облачная среда обеспечивает следующие возможности.
1. Автоматическое развёртывание всех компонентов CI/CD-инфраструктуры, включая Git-сервер (на базе Gitea), систему управления артефактами (Nexus), систему сборки и автоматизации (Jenkins), а также контейнерный кластер (Kubernetes). Все компоненты развертываются средствами управления конфигурацией без участия пользователя.
2. Построение многоступенчатого конвейера на языке сценариев Groovy, реализующего последовательную обработку изменений, доставляемых в Git-репозиторий. Обнаружение изменений инициирует цепочку: получение кода, сборка, тестирование, упаковка, публикация артефакта и его развертывание либо в контейнерной среде, либо на удалённом сервере.
3. Гибкий выбор целевого окружения развертывания. В зависимости от параметров сборки и конфигурационных переменных, система автоматически направляет артефакты либо в Kubernetes-кластер, либо на физические или виртуальные машины с операционными системами семейства Linux или Windows. Поддержка обоих направлений реализована в рамках одного общего пайплайна, что позволяет унифицировать обучение.
4. Поддержка многоконтурности. Разворачиваемая платформа позволяет моделировать различные уровни: разработка, испытания, предпромышленное развёртывание и эксплуатация. Все эти уровни конфигурируются автоматически и могут быть использованы в учебном процессе для демонстрации моделей жизненного цикла программных решений в реальных условиях.
Предполагается использование облачной среды для формирования непрерывной траектории подготовки специалистов в области ИТ — от первых курсов до аспирантуры, от базовых лабораторных работ до исследовательских проектов, включая участие в конкурсах, олимпиадах, стартап-программах. В настоящее время проводятся внутренние испытания сценариев на различных типах виртуальных и физических инфраструктур на базе аппаратных окружений Самарского национального исследовательского университета. Планируется апробация облачной среды в учебном процессе с последующим расширением за счёт новых шаблонов и улучшения сценариев масштабирования.
SUMMARY
The report presents a cloud educational environment with an automated CI/CD infrastructure based on open technologies. Its architecture and functionality are described. It is intended to use the cloud environment to form a continuous learning path for IT specialists - from first years to postgraduate studies, from basic laboratory work to research projects, including participation in competitions, olympiads and startup programs. Currently, internal testing of scenarios is being carried out on various types of virtual and physical infrastructures based on the hardware environments of Samara National Research University. It is planned to test the cloud environment in the educational process with subsequent expansion through new templates and improved scaling scenarios.
Introduction
With the rising prominence of Virtual Computer Laboratories (VCLs) and Learning Management Systems (LMS) such as Moodle [1–6], educational institutions face escalating demands on technical support services Repetitive inquiries from students, instructors, and administrators, coupled with the need for swift resolution of technical issues, necessitate innovative automation solutions. Conventional chatbots and FAQ pages often fall short, as they fail to account for course-specific nuances, user roles, and the dynamic context of VCLs. This paper introduces a novel automated response system grounded in a hybrid query-processing model that integrates Retrieval-Augmented Generation (RAG), a fine-tuned large language model (LLM) such as LIama or Gemma, and serverless architecture. The system seamlessly integrates with LMS Moodle and VCLs, leveraging platforms like Supabase, Render, Vercel, and Framer to deliver adaptive, context-aware responses, thereby alleviating the burden on technical support staff. The scientific novelty of this work lies in the synergistic combination of RAG based on PDF documents, role-specific adaptation, a self-learning mechanism, and an interactive interface, rendering the system uniquely suited for educational platforms.
The self-learning mechanism refers to a process whereby the system collects data on user interactions (questions, responses, and quality ratings), analyzes them, and employs these insights to refine system components, including the LLM and knowledge base. At its core, this mechanism enables the system to enhance the precision and relevance of responses over time by processing user feedback and fine-tuning the LIama or Gemma model with accumulated data. This adaptability ensures the system aligns with specific user queries, accounts for the context of VCLs and Moodle, and minimizes the need for human intervention in technical support.
Hybrid Query-Processing Model with LLM and Context-Aware Knowledge Base
The system integrates a large language model (e.g.,LIama or Gemma) with a localized knowledge base tailored to VCLs and LMS Moodle, enabling nuanced handling of user queries. This approach facilitates both general responses and context-specific answers that reflect course details, laboratory configurations, and common technical issues. Supabase serves as the repository for a structured knowledge base, encompassing question-answer pairs, error logs, and configurations for VCLs and Moodle, while supporting dynamic response updates based on user queries. Supabase’s pgvector extension enables efficient storage and retrieval of vectors (e.g., via cosine similarity), offering key advantages: rapid identification of relevant text snippets for input into LIama or Gemma and seamless integration with PostgreSQL, eliminating the need for standalone vector databases like Pinecone or Weaviate. Beyond embeddings, the system stores structured data, including question-answer pairs, PDF metadata (e.g., title, page), user profiles, and feedback logs. Supabase Storage provides S3-like object storage for uploading and managing PDF files, with Supabase Auth restricting access (e.g., to administrators only). Files are readily extracted for processing (e.g., via pdfplumber) on the Render server.
Adaptive Automation Tailored to User Roles
The system automatically identifies user roles (student, instructor, or administrator) through integration with VCLs, Moodle’s API, and Supabase Auth, tailoring responses to their access levels and technical requirements. Unlike most existing LMS chatbots, which overlook user role context, this system delivers customized outputs: step-by-step visual guides for students and technical scripts or server configurations for administrators, for instance.
Optimized Infrastructure for Scalability and Speed
A serverless architecture – leveraging Render for backend operations and Vercel for frontend delivery – combined with Supabase ensures real-time query processing, minimal latency, and scalability as user numbers grow. Framer, beyond its role as a design tool, serves as a platform for dynamically rendering responses with custom widgets, such as interactive Moodle interface diagrams or animated prompts, enhancing the user experience.
Self-Learning System Driven by Feedback
A feedback mechanism allows users to rate response quality, with the system utilizing these evaluations to fine-tune the model via Supabase Edge Functions. This iterative process improves the system’s understanding of Moodle-specific queries, boosting response accuracy over time.
Integration with Virtual Computer Lab
Beyond answering queries, the system provides interactive troubleshooting scenarios, such as code snippets for server configuration or links to relevant Moodle plugins. This functionality is particularly valuable for technical support, where actionable solutions, not merely text, are required.
System Architecture
• Supabase: Stores the knowledge base (questions, answers, error logs) and manages authentication. Edge Functions handle LLM queries and knowledge base updates.
• Render: Hosts the backend for complex tasks, such as Moodle log analysis or script generation.
• Vercel: Hosts the frontend, ensuring rapid interface loading.
• Framer: Delivers an interactive interface with custom widgets (e.g., visualizations of Moodle configuration steps).
• LLM: A locally deployed model (Llama or Gemma), fine-tuned on Moodle-specific data, generates tailored responses.
Operational Algorithm
• A user submits a query via the Framer interface.
• Supabase Auth identifies the user’s role (student, instructor, administrator).
• The query is processed by Supabase Edge Functions, which either retrieve a response from the knowledge base or forward the query to the LLM.
• The response is rendered in the interface with custom widgets (e.g., interactive guides).
• The user rates the response, with feedback stored in Supabase for fine-tuning.
Example Scenarios
• Student: “Why can’t I open a file?” The system verifies the user’s role, analyzes logs via the API, identifies the issue (e.g., incorrect file format), and provides a guide with an animated Framer prompt.
• Administrator: “How do I configure LDAP in Moodle?” The system delivers a script and documentation link, generated by the LLM and validated against the knowledge base.
Response Generation Process
A user submits a query via the Framer interface in Moodle (e.g., “How do I upload an assignment in Moodle?”) or a chatbot. The query is routed to the Vercel API, which mediates between the frontend and backend. Supabase Auth verifies the user and determines their role via Moodle’s REST API. Contextual details (e.g., Moodle version, course) are extracted to tailor the response. The query is converted into a vector representation using a lightweight model like all-MiniLM-L6-v2 (though alternatives like OpenAI models are viable). The query embedding is sent to Supabase, where the pgvector extension performs a cosine similarity search to retrieve the top 10 relevant text snippets (e.g., sections from Moodle’s manual) stored in a dedicated table. These snippets are combined into a context, forming a prompt that includes the user’s role, PDF-derived context, and the query. The fine-tuned Llama or Gemma model, trained on a custom dataset of VCL and Moodle question-answer pairs and PDF documents, generates a system-specific response. The response is adjusted based on the user’s role, and both the query and response are logged in Supabase’s knowledge base for analysis and fine-tuning.
Conclusion
The developed automated response system for VCLs and LMS Moodle represents a robust tool for optimizing technical support in educational settings. By integrating RAG with a fine-tuned Llama or Gemma model within a serverless architecture powered by Supabase, Render, Vercel, and Framer, the system achieves high accuracy (up to 90% post-fine-tuning) and reduces technical support response times by 70%. Its uniqueness stems from a hybrid query-processing model, role-adaptive responses, self-learning through feedback, and an interactive interface with custom widgets. Future enhancements include expanding the knowledge base with real-time Moodle log analysis, integrating lab assignments for automated scenario generation, and supporting multilingual documents. This development not only enhances the efficiency of educational processes but also sets a new benchmark for technical support automation in EdTech, showcasing the transformative potential of modern technologies in addressing real-world challenges.
References
1. Mitroshin P.A., Belov M.A. Metrics monitoring system of the educational process on the basis of e-learning. London, UK, 2024. С. 050015.
2. Grishko S., Belov M., Cheremisina E., Sychev P. Model for creating an adaptive individual learning path for training digital transformation professionals and Big Data engineers using Virtual Computer Lab // Creativity in Intelligent Technologies and Data Science / ed. Kravets A.G., Shcherbakov M., Parygin D., Groumpos P.P. Cham: Springer International Publishing, 2021. С. 496–507.
3. Belov M.A., Korenkov V.V., Potemkina S.V., Lishilin M.V., Cheremisina E.N., Tokareva N.A., Krukov Y.A. Methodical aspects of training data scientists using the data grid in a Virtual Computer Lab environment // CEUR Workshop Proceedings. 2019. Т. 2507. С. 236–240.
4. Belov M.A., Krukov Y.A., Mikheev M.A., Lupanov P.E., Tokareva N.A., Cheremisina E.N. Essential aspects of it training technology for processing, storage and data mining using the virtual computer lab // CEUR Workshop Proceedings. 2018. Т. 2267. С. 207–212.
5. Cheremisina E.N., Belov M.A., Tokareva N.A., Nabiullin A.K., Grishko S.I., Sorokin A.V. Embedding of containerization technology in the core of the Virtual Computing Lab // CEUR Workshop Proceedings. 2017. Т. 2023. С. 299–302.
6. Belov M.A., Tokareva N.A., Cheremisina E.N. The cloud-based virtual computer laboratory - An innovative tool for training // 1st International Conference IT for Geosciences. 2012.
В докладе представлена концепция системы, которая предназначена для создания распределенных приложений с общей персистентной памятью, что позволит значительно снизить затраты на разработку, поддержку и эксплуатацию.
Система синхронизации распределенного состояния (ССРС) - это система, состоящая из облачной платформы (PaaS) и комплекта для разработки ПО (SDK), которые осуществляют управление данными распределенного приложения. ССРС реализует абстракцию глобального состояния, обеспечивает его персистентность и реализует механизм конкурентного доступа, при этом не владет самим состоянием.
Для каждого рабочего процесса распределенного приложения система реализует абстракцию единого, централизованного, глобального для всего приложения состояния. В оперативной памяти каждого отдельно взятого рабочего процесса приложения может содержаться полная копия глобального состояния либо только та его часть, которая нужна бизнес-логике процесса. Процесс вносит изменения в глобальное состояние приложения путем упреждающей записи этих изменений в облачную часть ССРС, которая в свою очередь упорядочивает, сохраняет и распространяет эти изменения по всем процессам приложения. Так как изменения состояния, записываемые в систему, шифруются на уровне рабочих процессов, то только они владеют состоянием приложения.
Структуру состояния определяет разработчик приложений с помощью входящей в состав SDK библиотеки для соответствующего языка программирования. Библиотека предоставляет объектную модель данных, которая, в свою очередь, является нативной для языков программирования, удобной для человеческого восприятия и в целом универсальной. Также на уровне библиотеки реализован механизм конкурентного доступа к глобальному состоянию. Этот механизм позволяет единицам многозадачности приложения параллельно взаимодействовать с глобальным состоянием, читать и изменять его, при этом не мешая и не блокируя друг друга.
Таким образом, предоставляемые системой ССРС абстракция глобального состояния и механизм конкурентного доступа к нему сводят сложный и трудоемкий процесс разработки распределенного приложения к разработке одно-процессного приложения с общей памятью. Персистентность состояния позволяет отказаться от медленной внешней памяти и хранить все данные в оперативной памяти, что, в свою очередь, дает возможность определять структуру глобального состояния, используя объектную модель данных языка программирования.
На текущем этапе разработки нами проведена проверка концепции на примере приложения для распределенных вычислений [1, 2], спроектирован и реализован прототип веб-интерфейса пользователя системы.
SUMMARY
The paper presents a concept for a system designed to create distributed applications with shared persistent memory, which should significantly reduce development, support and operation costs. At the current stage of development, we tested the concept using an application for distributed computing [1, 2], and also designed and implemented a prototype of the system’s user web interface.
[1] Vostokin S., Rusin M.A. Experiments with the A022008 Sequence Generator to Study Distributed Computing Based on State Synchronization Service // Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). — 2025. — Vol. 15407 LNCS. — P. 75-89 (https://doi.org/10.1007/978-3-031-78462-0_6)
[2] Востокин С.В., Русин М.А. Метод кратковременного использования простаивающих компьютеров корпоративной сети для решения ресурсоемкой задачи // International Journal of Open Information Technologies. — 2025. — Т. 13. № 3. — С. 44-51 (http://www.injoit.org/index.php/j1/article/view/2052)
Доклад посвящён новому распределённому хранилищу данных, развернутому в Объединённом институте ядерных исследований для поддержки участия института в международных нейтринных экспериментах. Хранилище основано на системе dCache и интегрировано в экосистему многофункционального информационно-вычислительного комплекса Лаборатории информационных технологий им. М. Г. Мещерякова. В докладе рассматривается подход к управлению хранилищем, основанный на принципах методологии GitOps: декларативном описании инфраструктуры, её версионировании и отслеживании изменений конфигурации с использованием системы контроля версий Git. Будет рассмотрен применяемый стек технологий и регламенты работы — от организации хранения конфигураций и автоматизированного развёртывания до процедур проверки изменений перед их применением на рабочем кластере. Отдельное внимание уделяется системе мониторинга, включающей сбор метрик и оповещение на базе Prometheus, Grafana и Alertmanager, а также подходам к обеспечению отказоустойчивости и масштабируемости хранилища.
Согласно планам развития грид-сайта JINR Tier-1 в 2025 году был выполнен ряд задач по выбору аппаратного исполнения новых вычислительных серверов, применены новые подходы к мониторингу компонентов сервера, выполнены тесты производительности для потоковой обработки экспериментальных данных БАК. В докладе приводится краткий обзор прототипа системы мониторинга, сранительный анализ полученных данных.
Experimental data on filler metals is required in material science applications ranging from welding regime selection to numerical modelling of soldered joints behaviour. However, high-quality quantitative data is time-, cost-, and labour-intensive to produce.The present work proposes a method for the automated processing of full-text PDF articles in the field of material science that leverages visual, tabular, and textual data extraction techniques developed by the authors to obtain standardized representations of a selection of objects, thereby increasing the efficiency of technical data utilization. An integrative software tool built upon the method is discussed. The metrics of precision (63-99%) and recall (90-99%) calculated to assess tool performance prove the applicability of the solution proposed for domain-specific data aggregation, unification, search and management, and the potential for usage in science analytics systems.
The development of information and communication means of information delivery and the simplification of the ability of an individual to publish information have led to a significant increase in the amount of social data. The emergence of social networks, messengers in the 2000s led to an huge growth of content in the virtual environment. The information generated can be both true and false, can be distributed chaotically or have defined trajectories, can remain static over time or can change.
The paper considers the Internet environment as an information field in which there are information signals, which are understood as text, video and audio messages that possess by spreading in a given information field. The paper considers the segment of the global Internet network, in which crisis situations are possible, which means an unpredictable and critical aggravation of contradictions, problems or conflicts, which violates the normal order of things, threatens the security, stability and normal functioning of society, and requires immediate measures for their resolution and overcoming.
The paper develops models of dissemination of individual information messages in the Internet environment, as well as methods of software and hardware implementation of identification of information dissemination paths.
The article discusses the development of a request distribution system for large language models (LLMs) specialized in various scientific fields. The primary focus is on fine-tuning a controlling large language model that will identify scientific disciplines represented in textual data, thereby optimizing the processing and execution of requests while considering the specifics and requirements of particular scientific disciplines. The paper presents methods and algorithms aimed at improving the precision and speed of request processing, as well as enhancing interaction between the controlling language model and specialized scientific domain language models, for the efficient processing of large volumes of textual data.
Актуальность цифровых репозиториев публикаций как информационных систем, обеспечивающих доступность результатов научных исследований, сегодня невозможно переоценить. Особенно актуальны развитие и модернизация их функционала для автоматизированного сбора библиографических метаданных. В ОИЯИ отсутствие институционального цифрового репозитория подчеркивает важность решения этой проблемы. Эффективный доступ к актуальной информации о научных публикациях сотрудников, аффилированных с ОИЯИ, критически важен для оценки интеллектуального потенциала Института. Автоматизированные системы позволяют существенно сократить дублирование и ручной ввод данных о публикациях, упростить доступ к научной информации и повысить эффективность ее анализа. Современный репозиторий интегрирует данные из доверенных источников данных в единую систему, обеспечивает долговременное хранение и удобный доступ к информационным активам Института.
В докладе рассматриваются подходы к агрегированию результатов, полученных с использованием трех различных эмбеддинговых моделей при оценке семантической близости текстов. Исследуются следующие подходы к агрегации: усреднение косинусных расстояний, конкатенация эмбеддингов с последующим расчетом расстояний, а также выбор одного из трех косинусных расстояний на основе метода анализа главных компонент. Для анализа полученных результатов использовались статистические меры оценки, позволяющие выявить степень согласованности рассматриваемых подходов. Установлено, что наибольшее соответствие с исходными расстояниями демонстрирует метод усреднения косинусных расстояний. Полученные результаты могут быть использованы для повышения устойчивости моделей оценки семантической близости текстов при использовании ансамблей эмбеддингов.
Патентная документация является одним из ключевых источников информации об уровне научно-технических исследований в масштабах отдельной организации, отрасли или целой страны, подтвержденным экспертизой материалов на промышленную применимость, новизну и изобретательский уровень. Специфика структуры патентов, отражающая необходимость правовой защиты и охраны авторских прав, затрудняет их автоматизированный анализ и извлечение содержательных технологических взаимосвязей.
В работе представлена методика сбора и интеллектуального анализа патентных материалов для выявления и оценки ключевых и перспективных направлений исследований, определения технологических тенденций и инноваций на ранних стадиях их внедрения. Методика позволяет проводить исследования распределения патентной активности по компаниям-заявителям, авторам, регионам, технологическим областям и выявлять содержательные технологические взаимосвязи на основе статистического и семантического анализа текстов патентных материалов.
Апробация методики проводилась в рамках исследования одного из перспективных направлений, включающего квантовую и интеллектуальную робототехнику, которое отличается высокой инновационной активностью и существенным объемом патентной информации.
In computational molecular physics, the cornerstone of productive and precise research lies in the deployment of robust and purpose-fit scientific software. To fully exploit the capabilities of modern high-performance computing (HPC) architectures, it is imperative that such software be implemented in an optimized form to achieve maximal computational efficiency and scalability.
In this talk, we highlight our experience with two open-source quantum chemistry packages: DIRAC, a relativistic molecular code co-developed by one of the authors (M.I.) [1], and Quantum ESPRESSO, widely used for periodic DFT simulations [2].
We benchmarked various parallel configurations of DIRAC on the Govorun supercomputer and similarly evaluated Quantum ESPRESSO, including its GPU-enabled version. Test systems included molecule with superheavy element and periodic structure with superheavy addatom, both relevant to our group's current theoretical adsorption research.
Our objective in this talk is to share our practical insights on—how targeted optimization of DIRAC and Quantum ESPRESSO on HPC systems like Govorun can enhance computational performance and support efficient, large-scale simulations in quantum chemistry.
References
(1) Trond Saue, Radovan Bast, André Severo Pereira Gomes, Hans Jørgen Aa. Jensen, Lucas Visscher, Ignacio Agustín Aucar, Roberto Di Remigio, Kenneth G. Dyall, Ephraim Eliav, Elke Fasshauer, Timo Fleig, Loïc Halbert, Erik Donovan Hedegård, Benjamin Helmich-Paris, Miroslav Iliaš, Christoph R. Jacob, Stefan Knecht, Jon K. Laerdahl, Marta L. Vidal, Malaya K. Nayak, Małgorzata Olejniczak, Jógvan Magnus Haugaard Olsen, Markus Pernpointner, Bruno Senjean, Avijit Shee, Ayaki Sunaga, Joost N. P. van Stralen; The DIRAC code for relativistic molecular calculations. J. Chem. Phys. 29 May 2020; 152 (20): 204104. https://doi.org/10.1063/5.0004844
(2) Paolo Giannozzi, Oscar Baseggio, Pietro Bonfà, Davide Brunato, Roberto Car, Ivan Carnimeo, Carlo Cavazzoni, Stefano de Gironcoli, Pietro Delugas, Fabrizio Ferrari Ruffino, Andrea Ferretti, Nicola Marzari, Iurii Timrov, Andrea Urru, Stefano Baroni; Quantum ESPRESSO toward the exascale. J. Chem. Phys. 21 April 2020; 152 (15): 154105. https://doi.org/10.1063/5.0005082
The size and structure of discrete optimization problems remain a key limitation for existing solvers, as their computational complexity often scales exponentially with problem size. At QBroad, we have developed QIOPT (Quantum-inspired Optimizer), our proprietary solver capable of efficiently solving Quadratic Unconstrained Binary Optimization (QUBO) problems, which we have successfully applied in various technological and business fields.
In this work, we present Distributed QIOPT, a novel approach aimed at improving scalability by extending QIOPT through a decomposition strategy. Large optimization problems are partitioned into subproblems using heuristic methods and distributed across computational nodes of CloudOS, our cloud-based platform for high-performance computing. Each subproblem is solved independently, enabling parallelism and efficient use of resources. While initially developed for QUBO, this distributed optimization framework can be generalized to a broader class of discrete optimization problems. The proposed approach allows for obtaining high-quality solutions to large-scale problems that are otherwise intractable for conventional solvers.
In this study, we consider a scoring function [1] for evaluating the interaction energy of protein-protein complexes composed of two all-atom proteins. During the initial stage of interaction energy evaluation within a scoring function, interatomic distances are computed for all atom pairs located within a predefined cutoff threshold, prior to the calculation of potential energy terms. This stage can be formally formulated as follows.
Let $A$ and $B$ be datasets in three-dimensional space, containing $n$ and $m$ points, respectively. A distance similarity search, for a query point $q \in B$, consists of finding all points $a_{i} \in A$ such that $d(q, a_{i}) < \varepsilon$, where $d({\cdot},{\cdot})$ denotes the Euclidean distance function and $\varepsilon$ is a specified threshold. The process of identifying all pairs of points from two sets that lie within a specified threshold distance corresponds to performing a distance similarity join, with the resulting pairs stored in a result set.
In the simplest case, the task requires an exhaustive comparison of all point pairs with distance computation, resulting in a time complexity of $O(n{\times}m)$. Various approaches can be employed to construct the exact set of matching pairs, including tree-based data structures such as k-d trees and AABB trees, as well as specialized algorithms designed for this task, such as Super-EGO [2].
In this work, we consider an approach based on exhaustive pairwise comparison, accelerated using a graphics processing unit (GPU). This choice is motivated by the fact that GPU-based computations are also utilized in subsequent stages of scoring function evaluation. We present several GPU-based implementations employing both general-purpose CUDA cores and specialized Tensor cores which are a compelling alternative to CUDA cores, particularly with given dimension [3]. The problem formulation, implementation, and supplementary materials are available in the repository [4].
S. V. Poluyan, D. A. Nikulin, and N. M. Ershov, Development and Verification of a Score Function for Estimation of Intermolecular Interactions in Protein-Protein Complexes, in Proc. Int. Conf. on ITTMM, Moscow, Russia, April 17-21, 2023 (RUDN Univ., Moscow, 2023), pp. 231-235.
D. V. Kalashnikov, Super-EGO: Fast multi-dimensional similarity join, The VLDB Journal, 2013, doi: 10.1007/s00778-012-0305-7
B. Gallet and M. Gowanlock, Leveraging GPU Tensor Cores for Double Precision Euclidean Distance Calculations, 29th IEEE International Conference on High Performance Computing, Data, and Analytics, 2022, doi: 10.48550/arXiv.2209.11287
Supplemental materials - URL: https://vcs.uni-dubna.ru/dsj/test
UDC 004.896:681.518.5:658.562.012.7
Plotnikov A.A.¹,³, Milovidova A.A.¹,²
¹Dubna State University, Russia, 141980, Moscow Region, Dubna, Universitetskaya str., 19
²MIREA - Russian Technological University, Russia, 119454, Moscow, Vernadsky Ave., 78
³PJSC "TENSOR", Russia, 141980, Dubna, Moscow Region, Priborostroiteley str., 2
The article considers the concept of a multi-agent quality management system for technological processes integrated into modern SCADA systems. Developing approaches to intelligent quality management proposed by Milovidova A.A. and co-authors, the system implements a predictive forecasting mechanism for product quality changes based on analysis of raw material input parameters and equipment status. The architecture includes intelligent agents responsible for monitoring individual production areas, coordinating control actions, and adapting to changing conditions. A distinctive feature is the use of fuzzy logic for processing uncertainty in quality assessments and machine learning for continuous improvement of forecast accuracy. The proposed approach provides proactive quality management under conditions of input raw material characteristics instability. The system can be implemented as an intelligent add-on module for existing SCADA platforms, ensuring seamless integration with current industrial infrastructure while significantly enhancing decision support capabilities for production managers. The multi-agent architecture ensures system scalability and flexibility, allowing its adaptation to various industrial sectors, including mining, chemical, and food industries, where raw material quality variability presents significant challenges.
Monitoring system logs of computing complex servers is a pressing issue. Its solution can significantly increase the reliability level of the JINR MLIT MICC by providing advance warnings about possible emergencies. The report proposes a concept of a convenient tool for analyzing system log messages. Within its framework, programs for collecting and processing data, as well as an interface for their analysis, have been developed.
At the moment, the problem of the illegal export of children abroad is becoming increasingly relevant. One of the most difficult and dangerous aspects of this problem is the use of forged documents to carry out such actions. This practice not only violates the rights of children and their legal representatives, but also poses serious threats to the safety and well-being of minors. To protect children from illegal export abroad, a document is needed that includes not only documentary information, but also the child's biometric information, which will allow him to be accurately identified and increase the level of child safety.
In this paper, we propose a new format for a digital birth certificate, which contains a color photo of the child's face and characteristics of his facial biometrics, documentary information (full name of the child, year of birth, etc.), information about the educational institution, as well as the full names of the mother and father. Software has been developed that allows: to generate a digital birth certificate of a child in the form of a BIO QR code and in a GIF file, which makes it easier to view all the information, as well as embed documentary and biometric information in the form of QR codes in LSB layers of a color image of the child's face for storage in government databases.
Современные научные исследования невозможно представить без совместной работы над различными типами документов: статьями, презентациями, отчетами, тезисами и другими материалами. Доклад посвящен обзору новой программной платформы SciDocsCloud и созданного на её базе сервиса Объединенного института ядерных исследований (ОИЯИ) — Document Management Service (DocMS). Цель платформы — обеспечить создание централизованных, безопасных, надёжных и многофункциональных сервисов для хранения, управления и структурирования документов, а также организации совместной работы над ними. В ОИЯИ разработка SciDocsCloud ведется для замены устаревшей системы DocDB. Новая платформа учитывает опыт эксплуатации предыдущего решения, устраняет его выявленные недостатки и расширяет функциональные возможности. В докладе будут рассмотрены архитектура платформы SciDocsCloud и её ключевые компоненты, основной функционал сервиса DocMS и планы дальнейшего развития.
Добрынин В. Н. — профессор, кафедры САУ института САУ, ФГБОУ ВО «Университет «Дубна» (141980, Россия, Московская обл., г. Дубна, ул. Университетская, 19), кандидат технических наук, старший научный сотрудник, arbatsol@yandex.ru
Салов А.Н. — аспирант, ФГБОУ ВО «Университет «Дубна», Институт системного анализа и управления (141980, Россия, Московская обл., г. Дубна, ул. Университетская, 19), генеральный директор ООО «КСМК-М8», salov@mail.ru
Миловидова А. А. — кандидат технических наук, доцент кафедры САУ института САУ, ФГБОУ ВО «Университет «Дубна», доцент кафедры ЦТ ИИТ ФГБОУ ВО «МИРЭА - Российский технологический университет»
В условиях высокой неопределённости, роста сложности производственных процессов и ограниченных ресурсов становится очевидной необходимость перехода к интеллектуальному управлению производством. Распределённый интеллект в этих условиях превращается в базовую технологию повышения устойчивости и эффективности управления. Одним из ключевых инструментов интеллектуализации производства являются многоагентные системы (МАС). Они позволяют реализовать автономное управление каждым этапом технологического процесса с помощью специализированных программных агентов, обеспечивая гибкость, устойчивость и адаптацию всей производственной системы.
Интеллектуализация коллективной деятельности возможна благодаря горизонтальной и вертикальной интеграции агентов на всех уровнях — от оборудования до корпоративного планирования. Такая координация создаёт основу для трансформации в полноценную Smart Factory. На практике это подтверждается успешным внедрением МАС на предприятии по производству ячеистого бетона, где система показала высокую эффективность, масштабируемость и интеграцию с ERP. Это демонстрирует готовность предприятия к переходу в формат умной фабрики.
Перспективы развития многоагентных систем связаны с внедрением методов машинного обучения и предиктивного планирования. Самообучающиеся агенты и интеллектуальные механизмы прогнозирования спроса позволят стратегически управлять производственными процессами и запасами. Особенно актуальна эффективность МАС в условиях нелинейной технологической схемы, где сбой в одном участке влияет на всю систему — агенты обеспечивают динамическую коррекцию в реальном времени.
Производственные процессы включают десятки критически важных переменных, и МАС способны параллельно анализировать и регулировать их, предотвращая накопление отклонений и снижая потери. Интеллектуальные агенты также адаптируют параметры в зависимости от колебаний характеристик сырья и полуфабрикатов, что значительно снижает уровень брака. Система демонстрирует высокую устойчивость к внешним и внутренним сбоям благодаря локальному реагированию агентов, что позволяет поддерживать непрерывность производства и высокое качество продукции.
МАС обеспечивают гибкость в условиях высокой рыночной конкуренции, позволяя быстро адаптироваться к новым требованиям, минимизируя время реакции и повышая устойчивость к внешним угрозам. При этом они ускоряют запуск новых продуктов на рынок, моделируя производственные цепочки и снижая затраты на ввод новых товарных позиций. Прогнозирование спроса и адаптация объёмов и ассортимента производства способствует снижению складских издержек и излишков. Более того, использование МАС позволяет перейти от массового производства к кастомизированному выпуску продукции под конкретные запросы клиентов.
Всё это реализуется на основе комплексной динамической адаптивной модели, учитывающей как технологические, так и организационные параметры. Такая модель обеспечивает непрерывную настройку производственного процесса в реальном времени, позволяя гибко реагировать на вызовы и обеспечивать стабильное развитие предприятия в цифровую эпоху.
Комплексная динамическая адаптивная модель производства выступает как ядро интеллектуального управления, объединяя технологические, организационные и информационные компоненты в единую саморегулирующуюся систему. Её основная функция — обеспечить синхронизацию всех уровней производственного процесса, от цехового управления до корпоративного планирования, в режиме реального времени. Такая модель позволяет оперативно реагировать не только на текущие производственные отклонения, но и на стратегические изменения внешней среды: колебания спроса, перебои в поставках, изменение характеристик сырья и нестабильность рыночной конъюнктуры.
Ключевой особенностью модели является её обучаемость и способность к самонастройке. Система не только собирает и анализирует данные с оборудования, логистики и продаж, но и использует эти данные для адаптации алгоритмов управления. Это позволяет реализовать предиктивные сценарии: от прогнозирования износа оборудования и своевременного техобслуживания до оптимизации производственного графика под будущий спрос. Таким образом, модель формирует проактивный, а не реактивный стиль управления.
Кроме того, модель поддерживает модульный принцип построения, благодаря чему её можно поэтапно внедрять и масштабировать под особенности конкретного предприятия. Это делает её применимой как в крупносерийном производстве, так и в условиях высоко переменного, кастомизированного выпуска. В результате предприятие получает инструмент, который не только повышает производственную эффективность, но и обеспечивает адаптивность, устойчивость и готовность к трансформации в условиях цифровой экономики.
Такой подход создаёт новую парадигму управления производством — не просто автоматизированную, а интеллектуальную, где система способна учиться, прогнозировать и принимать решения в сложной, быстро меняющейся среде.
Современные вызовы цифровой трансформации требуют подготовки инженеров искусственного интеллекта, способных не только работать с передовыми технологиями, но и решать комплексные междисциплинарные задачи в условиях быстро меняющихся требований отрасли. Цель исследования — создание цифровой образовательной среды, интегрирующей инструменты и методологии, обеспечивающие системную и практико-ориентированную подготовку специалистов в области инженерии ИИ.
Ключевым компонентом инфраструктуры выступает виртуальная лаборатория, предоставляющая доступ к распределённым вычислительным ресурсам и современным фреймворкам (TensorFlow, PyTorch, Scikit-learn, Apache Spark, Hadoop и др.). Учебные кейсы разработаны с учётом матрицы профессиональных компетенций, сформированной на основе анализа более 100 вакансий AI/ML-специалистов и охватывают широкий спектр задач: от основ нейросетей до трансформеров, генеративных моделей и интеллектуальных чат-ботов.
Исследование базируется на системном подходе, который предполагает формализацию научных проблем, иерархическое представление задач, создание единого методологического пространства и языка взаимодействия между участниками. Особое внимание уделено базовым задачам ИИ: ретрогнозу, прогнозу, поиску, разведке, классификации и построению. Для их решения применяются алгоритмы кластеризации, регрессионного анализа, методы отбора признаков и редукции размерности, а также нейронные сети, включая RNN, LSTM и глубокие CNN.
В исследовании подчёркивается важность подготовки студентов к решению мультидисциплинарных задач, характерных для слабоформализованных наук — экологии, медицины, геологии, государственного муниципального управления и др. Такие задачи требуют не только владения ИИ-инструментами, но и умения формулировать задачи, переводить их на формализованный язык данных, разрабатывать соответствующий инструментарий и интерпретировать результаты с учётом прикладного контекста.
Результаты апробации показали рост качества усвоения материала, формирование устойчивых практических навыков и высокий уровень мотивации студентов. Виртуальная лаборатория обеспечила гибкость и масштабируемость обучения, что особенно важно для подготовки специалистов в условиях постоянного технологического обновления.
Таким образом, проведённое исследование представляет собой инновационный образовательный комплекс, объединяющий современные технологии, системное мышление и прикладной фокус. Оно не только отвечает актуальным требованиям рынка, но и закладывает фундамент для подготовки специалистов, способных решать задачи будущего на стыке науки, технологий и общества.
